Università degli Studi "La Sapienza"
Facoltà di Informatica
Cattedra di Sistemi Operativi I
|
SCAMBIO DI MESSAGGI A LUNGHEZZA VARIABILE |
Docenti:
Prof. Luigi V. Mancini
Dott. Pietro Cenciarelli
|
Studenti: Simone Federici Fabio Caponi Gregorio Convertino |
Indice
degli argomenti
2. Struttura dati del buffer
2.1 La gestione della coda circolare
2.2 Inserimento e cancellazione dei messaggi
3. Le politiche di gestione del buffer
3.1. Aspetti in comune tra le politiche
3.1.1 Sequenza degli eventi
3.1.2 I metodi sincronizzati
3.2. Mancanza di politica (politica anarchica)
3.2.1 Considerazioni
3.3 La politica FIFO
3.3.1 Considerazioni
3.4. La politica personalizzata
3.4.1 La prima alternativa considerata
3.4.2 La seconda alternativa considerata
3.4.3 L’ultima alternativa considerata
3.4.4 Considerazioni
4. Il Simulatore
4.1 Lettura da File
4.2 Fattore alpha
4.3 Fattore beta (tempo medio di interarrivo)
4.4 Tempo Reale
5. L’interfaccia grafica
5.1 L’interfaccia di input
5.2 L’interfaccia di output
5.3 I grafici in output
6. Organizzazione del codice
6.1. Il pacchetto BUFFER
6.2. Il Pacchetto SIMULA
6.3. Interfaccia grafica di input
7. Manuale d’uso
8. La rilevazione dei dati
8.1. Nel corso della simulazione
8.2. A fine simulazione
9. Risultati
9.1. Metodo
9.2. Elaborazione dei dati
9.3. Osservazioni
10. Download Codice Java in Formato Zip
11. Download Codice Java in Formato tar.gz
Lo scopo di questo progetto è di realizzare, mediante il linguaggio di programmazione Java, un simulatore per l’analisi di politiche d’accesso ad un buffer a capacità limitata, il quale viene condiviso tra processi destinatari e mittenti che si scambiano messaggi a lunghezza variabile.
Precisiamo innanzitutto che con messaggio s’intende una qualsiasi stringa avente al massimo 200 caratteri. Questi vengono scambiati mediante un buffer condiviso avente una capacità di 200 caratteri. Le sole operazioni consentite sul buffer sono quelle di scrittura (put) e lettura (get).
Prima che iniziasse la progettazione del simulatore è stato necessario comprendere a pieno i criteri guida previsti per questo progetto. Perché questi divenissero chiari del tutto è stato molto utile lo scambio dialettico avuto con i didatti, i quali sono stati disponibili a fornire tutti i chiarimenti necessari.
Anche lo stesso lavoro di progettazione ha progredito per successive ridefinizioni ed arricchimenti delle soluzioni adottate, grazie al contributo di ognuno tre membri del gruppo di lavoro.
La struttura dati che è stata usata per il buffer è un vettore di 200 caratteri gestito come coda circolare. L’uso di questa struttura è stato principalmente motivato dalla facilità di gestione e perché permette, per le caratteristiche del vettore, di usare sempre la stessa quantità e parte di memoria.
2.1 La gestione della coda circolare
Per gestire la coda circolare sono state usate due variabili intere chiamate in e out. Queste costituiscono l'indice di scrittura e l'indice di lettura. Per poter differenziare il caso in cui la coda è vuota da quello in cui essa è piena, ossia quando l’indice in è uguale all’indice out, è stata introdotta una terza variabile intera chiamata liberi. Questa indica quanto spazio disponibile è presente nel buffer. L’informazione che la variabile fornisce servirà a gestire adeguatamente l'inserimento e la cancellazione dei messaggi: il messaggio che si intende inserire non dovrà superare lo spazio libero a disposizione (liberi >= lunghezza del messaggio) e non potrà essere letto alcun messaggio qualora il buffer sia vuoto (liberi == 200).
L’inserimento e la cancellazione dei messaggi all’interno del buffer avvengono carattere per carattere, incrementando di volta in volta l’indice specifico. In particolare, la circolarità della coda implementata con un vettore, obbliga l’uso dell’operazione modulo n (n=200) ad ogni incremento degli indici. Di conseguenza questi potranno assumere valori compresi tra 0 e 199.
2.2 Inserimento e cancellazione dei messaggi
È stato usato un vettore ausiliario di 200 numeri interi di tipo short per memorizzare il valore della lunghezza di ogni messaggio che viene inserito. Questo secondo vettore verrà gestito mediante gli stessi indici in e out utilizzati nel vettore-buffer.
Durante una operazione di scrittura verrà, in primo luogo, memorizzata la lunghezza del messaggio nel vettore ausiliario, in corrispondenza del valore indicato da in e, successivamente, verrà inserito il messaggio nel vettore-buffer.
Una operazione di lettura prevede, invece, che prima venga letto il valore indicato dall’indice out nel vettore ausiliario e che dopo sia letto dal vettore-buffer il messaggio corrispondente la cui lunghezza è pari al valore suddetto.
3. Le politiche di gestione del buffer
3.1. Aspetti in comune tra le politiche
Un evento è l’invocazione di un processo di scrittura o lettura sul buffer. Questo costituirà l’unità di misura del tempo virtuale. Si è scelto di definire l’evento in rapporto alla sola invocazione di un processo in quanto, qualora tale processo venisse addormentato e poi risvegliato, non produrrebbe un ulteriore evento.
Vengono create due distinte liste di oggetti una per i processi scrittori (put) ed una per quelli lettori (get). Ogni lista permette di ricordare la sequenza degli eventi mantenendo i processi nell’ordine di arrivo mediante una variabile globale che "referenzia" sempre l’ultimo oggetto della lista.
In ogni oggetto viene inoltre memorizzato, in un primo campo, il numero di eventi passati prima dell’invocazione e, in un secondo, il numero degli eventi passati fino al termine dell’esecuzione del processo considerato. Il tempo virtuale di esecuzione di un singolo processo è quindi dato dalla differenza tra i valori presenti nei due campi (e cioè, il numero accessi al buffer intercorsi durante l’esecuzione del processo + l’evento stesso).
Tutte le politiche di seguito considerate ricorrono a metodi sincronizzati dovendo gestire più processi attivi simultaneamente.
Utilizziamo i metodi put e get sincronizzati (sul buffer) in modo che si possa eseguire una ed una sola operazione di scrittura o di lettura alla volta. Sarebbe problematico gestire operazioni in multithread in assenza di questo tipo di metodi, poiché due o più processi eseguiti contemporaneamente potrebbero causare perdita di dati.
Così come prevede il metodo sincronizzato nel linguaggio Java, un processo mittente, dopo aver preso il lock, controlla se la lunghezza del messaggio è minore o uguale allo spazio disponibile nel buffer, nel caso in cui ciò é vero il messaggio viene memorizzato. Qualora ciò non si verifichi, però, il processo si addormenta rilasciando il lock. Quando viene liberato spazio nel buffer a seguito di un processo di lettura o destinatario (get), uno a caso tra i processi mittenti eventualmente in attesa (con messaggio che non superi lo spazio disponibile) viene riattivato. Un processo destinatario, invece, si addormenta nel caso in cui il buffer sia vuoto.
Nel momento in cui un processo mittente o destinatario termina, risveglia tutti i processi precedentemente addormentati sul buffer.
3.2. Mancanza di politica (politica anarchica)
La politica viene chiamata anarchica in quanto i processi di lettura e di scrittura non devono sottostare a nessun vincolo fuorché quello di considerare, i primi, che il buffer non sia vuoto e, i secondi, che ci sia spazio disponibile sufficiente.
Ipotizzando un numero infinito di processi mittenti e destinatari che operano sul buffer, i processi che volessero scrivere messaggi molto lunghi, dovendo aspettare che nel buffer si liberi una quantità di spazio sufficiente, superati da messaggi di minor lunghezza, potrebbero attendere un periodo di tempo indefinito (attesa indefinita). Lo stesso tipo di attesa potrebbe verificarsi anche per i processi destinatari. Questi, trovando ripetutamente il buffer vuoto, verrebbero sistematicamente riaddormentati, mentre negli intervalli di tempo in cui questi sono dormienti altri processi destinatari avrebbero libero accesso al buffer. È tuttavia questa un’eventualità che non si verifica qualora il tempo medio di esecuzione dei destinatari è sempre maggiore di quello dei mittenti (alpha).
La politica Fifo (First-in-first-out) è una particolare modalità di gestione delle attese dei processi. Il primo processo che arriva è il primo processo che scrive sul buffer. Se non può essere eseguito (liberi < lunghezza del messaggio), si addormenta e aspetta fino a che non si libera abbastanza spazio mentre tutti gli altri processi che arrivano gli si mettono in coda. Per risvegliare il processo giusto, bisogna stabilire un ordine di arrivo tra i processi, assegnandogli di volta in volta un numero (1, 2 , 3, …., n). Vi è quindi un variabile di controllo che stabilisce il numero d’ordine del processo che dovrà essere eseguito. Terminato un processo, la variabile viene incrementata e vengono risvegliati tutti i processi che dormono. Uno alla volta i processi, dopo aver preso il lock, controlleranno che il loro numero d’ordine corrisponda a quello della variabile di controllo e che vi siano le condizioni per accedere al buffer. Viene quindi eseguita l’operazione sul buffer risvegliando nuovamente tutti i processi e incrementando la variabile di controllo. Questa sequenza verrà ripetuta finché ci saranno processi a disposizione.
Questa politica gestisce le attese simulando una coda di thread. Essa elimina l’attesa indefinita. Infatti, ipotizzando un numero infinito di processi mittenti e destinatari che operano sul buffer, si può affermare che ogni processo verrà eseguito in un numero finito di passi. Tuttavia, i processi che, sebbene arrivati più tardi, avrebbero potuto accedere al buffer (messaggi sufficientemente corti) in una sola unità di tempo, sono costretti ad una attesa non necessaria.
3.4. La politica personalizzata
La politica personalizzata è stata scelta dopo un’attenta disamina di alcune possibili alternative. Queste però hanno riguardato solo ed esclusivamente la gestione dei processi mittenti. Per i processi destinatari, invece, non viene seguita alcun tipo di politica (anarchica).
3.4.1 La prima alternativa considerata
Inizialmente, ad ogni risveglio di un processo precedentemente addormentato, il sistema controlla quanti eventi sono passati dal suo primo tentativo di accedere al buffer. Se questa quantità supera il valore di tolleranza ricevuto in input, la politica di gestione, finora anarchica, viene temporaneamente sostituita da un’altra politica, di tipo analogo a quella FIFO, che da la precedenza al processo considerato, mettendo in coda tutti i processi arrivati successivamente, ma mantenendo il loro ordine d’arrivo. Questa politica rimarrà attiva fino a quando la coda di processi non si esaurisce.
E’ questa, però, una politica che non coglie correttamente per tutti i processi, quando questi hanno atteso più del valore previsto dalla tolleranza. Potrebbero infatti verificarsi tantissimi eventi prima che il sistema dia il lock al processo e questo effettui il suo controllo.
3.4.2 La seconda alternativa considerata
Analogamente alla precedente soluzione, questa politica sfrutta sempre un vincolo di tolleranza comportandosi in modo anarchico, ma contando i processi in attesa. Qualora venga superata la soglia della tolleranza, presa in input, in questo caso vengono bloccati tutti i nuovi processi fino a quando quelli in attesa abbiano compiuto la loro operazione sul buffer.
Il difetto peculiare di questa politica è la presenza di alcune attese indefinite. Ad esempio, nel caso in cui i messaggi sono molto corti e il buffer non si riempie, l’unico messaggio molto lungo, presente nel file, potrebbe avere una attesa indefinita. Questo poiché il numero di processi addormentati nel buffer non raggiungerebbe mai la tolleranza.
3.4.3 L’ultima alternativa considerata
Questa politica è analoga alle precedenti per quanto concerne l’utilizzo di una politica anarchica in condizioni di non "affollamento" dei processi sul buffer.
Le soluzioni precedentemente considerate imponevano un limite all’attesa dei processi in termini di un valore di tolleranza settato da input. Seppure anche in questa soluzione venga imposto un limite all’attesa, tuttavia il controllo avviene in modo diverso.
Ogni volta che un processo termina il sistema verifica se il processo in testa alla coda ha atteso un numero di eventi superiore a quello previsto dal valore di tolleranza. Se ciò è vero, interviene bloccando tutti i processi fuorché quello in testa. Questo quindi, essendo l’unico ad avere accesso al buffer, lo userà. Tutti i processi che arriveranno nel frattempo verranno messi in coda. E’ importante precisare che questa coda non si comporta strettamente secondo una modalità FIFO, perché i processi in attesa possono uscirne in due situazioni possibili:
- Quando, trovano nel buffer lo spazio sufficiente.
- Quando durante la loro attesa sono arrivati in testa alla coda e sono passati un numero di eventi superiori al valore di tolleranza. (Bloccando tutti i processi in ingresso).
Se il processo che accede al buffer fa parte della coda, allora esso dovrà essere eliminato da questa. Nel fare ciò possono presentarsi tre possibili situazioni a seconda che il processo sia in testa, in coda o in posizione intermedia. Perché la cancellazione del processo nelle tre diverse posizioni fosse semplice da effettuare, è stata usata, come struttura dati per la coda, una lista ‘linkata’ in cui ogni elemento ha un "referenziamento" sia al precedente che al successore.
Questa terza ed ultima politica considerata risulta essere la più efficiente poiché elimina le attese indefinite e riduce notevolmente le attese inutili. In essa vengono risolti i problemi che insorgevano nelle precedenti soluzioni. Ricordiamo, infatti, che la prima, seppure basata sugli stessi principi, non effettuava un controllo uniforme per tutti i processi e la seconda, invece, non eliminava del tutto l’eventualità delle attese indefinite.
Il simulatore progettato prende in input i seguenti dati:
- un file di testo;
- il fattore alpha;
- il fattore beta (interarrivo);
- la politica scelta;
- la tolleranza (se la politica scelta è quella personalizzata);
Il file in input viene spezzettato in token, ognuno dei quali sarà un messaggio da inviare al buffer.
Viene creato un vettore di n processi destinatari (n è il numero di token). Viene poi creato e lanciato un nuovo thread che, in parallelo a quello principale, lancerà gli n processi destinatari del vettore che eseguiranno ognuno una operazione get. Nel frattempo il thread principale lancerà n processi mittenti che eseguiranno ognuno una operazione put, passando come parametro un token.
Vengono quindi controllati, uno ad uno, gli n elementi del vettore (processi destinatari) finché tutti i loro rispettivi processi non avranno terminato la loro esecuzione.
A questo punto viene visualizzata una interfaccia grafica che riassume i dati rilevati.
Verranno ora esaminati più in dettaglio gli input ed il loro utilizzo.
Il contenuto del file verrà copiato in un array di byte, convertito in una stringa e "tokenizzato" (spezzettato in stringhe) usando come delimitatori lo spazio, la tabulazione e l’invio. Ognuno di questi token sarà un messaggio da inviare al buffer.
Per simulare che i processi mittenti arrivino più velocemente di quelli destinatari, viene preso in input un fattore alpha (alpha > 1) di tipo float che moltiplicato per il tempo di sleep dei processi destinatari, ne rallenta l’esecuzione.
4.3 Fattore beta (tempo medio di interarrivo)
Nell’ambito di processi che chiamano uno stesso metodo (get o put), con tempo di interarrivo si intende il tempo che intercorre tra due di queste chiamate. Nel caso qui considerato il simulatore riceve in input un valore specifico di tempo medio di interarrivo in millisecondi.
In un sistema reale il tempo medio di interarrivo risulterebbe essere un indice di tendenza centrale che riassume la distribuzione dei tempi di interarrivo dei singoli processi.
Lo scopo di questo simulatore è di descrivere le diverse eventualità che possono verificarsi in una situazione reale.
Dati in input un fattore beta e il numero dei processi, n°proc, che dovranno interagire con il sistema, siamo in grado di calcolare un valore Max tale che, se ogni processo dormisse tra zero e tale valore e vi fosse una distribuzione omogenea dei tempi di sleep (intervallo di tempo in cui i processi rimangono dormienti) in questo intervallo, il tempo medio di interarrivo tra i processi risulterebbe essere pari al fattore beta.
beta = Max / n°proc = tempo medio di interarrivo (ca.)
La differenza tra l’ora esatta (millisecondi) di quando termina l’ultimo processo destinatario con l’inizio del primo processo mittente, ci da il tempo totale di esecuzione. Dividendo tale cifra con il numero di processi lanciati, si ottiene il tempo medio di esecuzione di un processo. Per sapere quanti processi sono stati eseguiti in un secondo, si divide il numero di processi con il tempo totale di esecuzione.
Sono state implementate delle finestra del pacchetto AWT (Abstract Window Toolkit) che estendono un frame. Un oggetto frame è una finestra vuota, composta solo dalla barra di titolo.
|
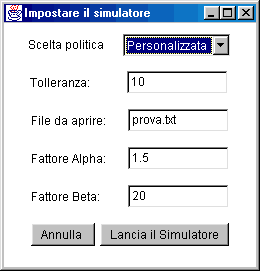
L’interfaccia di input permette all’utente di scegliere i parametri per la simulazione. La politica viene scelta mediante un menù a tendina. Vi sono inoltre tre campi di testo (text-field), in cui inserire il nome del file di input, il fattore alpha e il fattore beta. Nel caso in cui la politica scelta è quella personalizzata, l’interfaccia fornisce un ulteriore campo di testo in cui poter specificare il valore della tolleranza utilizzato in tale politica. |
|
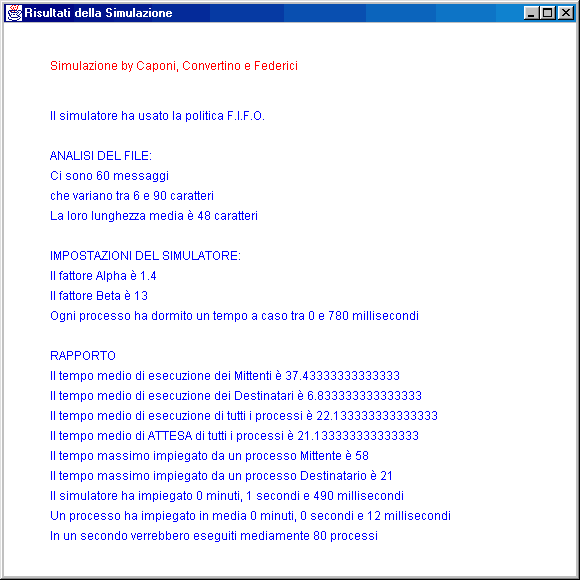
Questa finestra riassume i dati rilevati durante il corso della simulazione
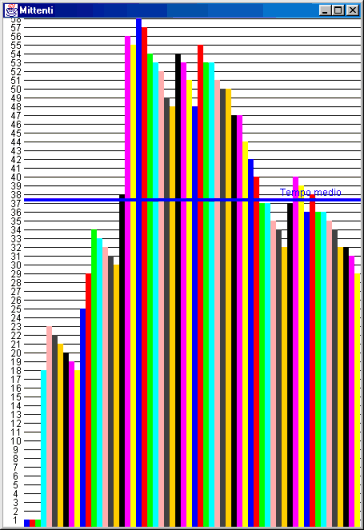
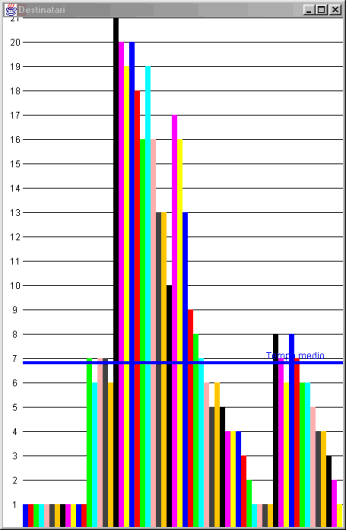
Il grafico rappresenta i tempi virtuali di esecuzione dei processi mittenti o di quelli destinatari, in ascisse vi sono i processi nell’ordine di arrivo e nelle ordinate il numero di eventi.
|
|
Il programma è suddivisibile in tre parti distinte:
- Un pacchetto BUFFER che comprende tutti i file per la gestione del buffer.
- Un pacchetto SIMULA che contiene i file per il simulatore e per l’interfaccia grafica di output: grafici e finestra di testo con i risultati riassuntivi.
- L’interfaccia grafica per l’immissione dei dati.
- simulator.java corpo del simulatore, lancia Maingetter e n putter passandogli un messaggio letto dal file
- Maingetter.java lancia in parallelo a simulator n getter
- getter.java processo lettore
- putter.java processo scrittore
- grafico.java: classe che estende Frame per visualizzare graficamente i tempi di esecuzione dei processi.
- fine.java: classe che estende Frame per visualizzare una finestra di testo su cui sono riassunti i risultati.
6.3. Interfaccia grafica di input
Il simulatore utilizza un’interfaccia grafica dove è possibile settare:
- la politica da usare
- il nome del file da dove prendere i messaggi
- il fattore alpha (velocità relativa tra mittenti e destinatari)
- il fattore beta (tempo medio di interarrivo)
Questi settaggi possono essere impostati da tastiera.
Due parametri sono stati introdotti per velocizzare le simulazioni, questi possono essere settati solo da tastiera. Essi sono –NOGRAPHICS (che non visualizza le tre finestre di output) e –r=<ripeti>, dove ripeti è il numero di volte che la simulazione viene ripetuta.
Questo è il manuale visualizzato sul terminale quando richiesto dall’utente.

8.1. Nel corso della simulazione
Il simulatore in simultanea con l’esecuzione dei processi, fornisce stampando sul monitor e su un file (output.txt) il resoconto delle attività in corso.
Al termine di ogni simulazione, il sistema fornisce in output su una finestra di testo i seguenti dati:
- Informazioni derivanti dall’analisi del File:
- Numero di messaggi presenti
- Range di variazione della lunghezza dei messaggi
- Lunghezza media dei messaggi
- Tempo virtuale medio di esecuzione dei mittenti
- Tempo virtuale medio di esecuzione dei destinatari
- Tempo virtuale medio di esecuzione dei processi
- Tempo virtuale medio di attesa dei processi
Due grafici che descrivono rispettivamente i tempi di esecuzione dei mittenti e quelli dei destinatari.
Due file di testo (mittenti.txt e destinatari.txt) su cui sono registrati rispettivamente i tempi di esecuzione dei mittenti e quelli dei destinatari.
Il sistema registra, inoltre, le informazioni salienti derivate da ogni singola simulazione su un file di testo presente nella directory Statistiche. Ad ogni esecuzione corrisponderà nel file di testo una singola riga di dati. Il nome di questo file riassume sinteticamente i parametri dati in input per la simulazione da cui esso è stato generato. Esso infatti è così costituito: la prima lettera indica la politica (A per anarchica, F per FIFO, e P per personalizzata), le cifre immediatamente successive specificano il valore della tolleranza. Un trattino separa queste dal valore del fattore alpha . Dopo un altro trattino è indicato il valore di beta e, infine, dopo un ulteriore trattino vengono visualizzati i due primi caratteri del nome del file dato in input.
Una volta completata la progettazione del sistema, sono state create due varianti all’iter di esecuzione appena descritto:
- Una, attivabile mediante il flag –nographics, in cui, al termine della simulazione non venissero visualizzati in output né la finestra di testo né i due grafici che visualizzano riassuntivamente i risultati ottenuti.
- un’altra, attivabile mediante il flag –r=n, (dove n è il numero di iterazioni) la quale itera il processo di simulazione, a partire dai parametri dati in input, un numero di volte pari al valore n specificato nel flag.
Grazie a queste due varianti è stato possibile raccogliere i dati sulle simulazioni in modo rapido e sistematico.
Presenteremo qui di seguito le variabili indipendenti, dipendenti e di controllo considerate nell’ambito della sperimentazione.
Le variabili indipendenti sono:
- la politica di gestione del buffer,
- la tolleranza,
- il fattore alpha (velocità relativa tra i processi mittenti e quelli destinatari),
- il fattore beta (tempo di interarrivo)
- la lunghezza media delle parole
E’ stata considerata come variabile di controllo da tenere in considerazione il numero di messaggi che componevano il file dato in ingresso al simulatore. Ciò perché i risultati derivanti dai vari file dati in ingresso fossero confrontabili tra loro.
Sono poi state misurate le seguenti variabili dipendenti:
- tempo reale di esecuzione (misurato in millisecondi);
- tempo virtuale medio (misurato in eventi)
- di esecuzione di un processo mittente;
- di esecuzione di un processo destinatario;
- di attesa di un singolo processo.
Le simulazioni, condotte variando un singolo parametro per volta, prevedevano dieci iterazioni per ogni prova. Questo per garantire che le variazioni dovute al caso venissero a compensarsi tra loro. L’annullarsi di questa fonte di variazione ha permesso così di isolare il solo contributo delle variabili indipendenti.
Il programma delle sperimentazioni può essere riassunto come segue: sono stati utilizzati tre file di testo di 400 messaggi ognuno.
- 01prova.txt: messaggi di lunghezza tra 1 e 18 caratteri (5 di media)
- 02prova.txt: messaggi di lunghezza tra 4 e 200 caratteri (50 di media)
- 03prova.txt: messaggi di lunghezza tra 60 e 200 caratteri (150 di media)
Per ogni file è stato effettuato un programma di prove in cui sono stati confrontati i risultati tra le diverse politiche a parità di parametri alpha e beta . Per quanto riguarda la politica personalizzata, essa è stata eseguita ogni volta per quattro diversi valori di tolleranza. Ogni singola prova consisteva in dieci distinte simulazioni con gli stessi parametri. Sono state effettuate prove distinte per quattro diversi valori di beta e per due diversi valori di alpha.
Dall’esame dei risultati delle singole prove (valori medi su dieci simulazioni), emergono alcune considerazioni di carattere generale.
Per quanto riguarda il variare di beta (tempo medio di interarrivo), si può osservare che, all’aumentare di questo valore, diminuisce il tempo virtuale medio di attesa dei processi e aumenta il tempo reale di esecuzione della simulazione. Quest’ultimo, però, aumenta solo a partire da un valore "ottimale" di beta che nel nostro caso risulta collocarsi tra 5 e 10 a seconda della lunghezza media dei messaggi che compongono il file in input. Il valore ottimale si alza all’aumentare della lunghezza media dei messaggi.
Si può inoltre osservare, così come era previsto, che all’aumentare del valore di alpha i tempi medi di esecuzione dei destinatari si abbassano e i tempi di esecuzione (virtuale e reale) aumentano.
Per quanto riguarda le politiche di gestione del buffer si può osservare che l’assenza di politica (politica anarchica) è la migliore sia in termini di tempo virtuale che in termini di tempo reale. Questo però si evidenzia man mano che il valore di alpha si avvicina a 1 e/o il valore di beta diminuisce.
Generalmente, premesso che le differenze tra le politiche si annullano all’aumentare di beta, i risultati ottenuti con la politica personalizzata risultano essere comparabili o peggiori rispetto a quelli ottenuti con la politica FIFO. Tuttavia, la politica personalizzata riesce ad ottenere risultati migliori rispetto a quella FIFO quando la lunghezza media dei messaggi in ingresso ed il valore di beta sono particolarmente bassi (vedi grafico sui tempi medi di attesa per beta =1 del file 01prova.txt.) e ciò accade in corrispondenza di valori di tolleranza alti.
Aumentare beta significa imporre un intervallo di tempo maggiore tra i processi che arrivano sul buffer. Ciò comporta un ritardo dell’esecuzione complessiva della simulazione, spiegando così l’aumento dei tempi reali. Per valori di beta inferiori a quello ottimale, però, accade che arrivino troppi processi contemporaneamente che non riescono a essere gestiti creando anche qui un ritardo nell’esecuzione. Parlando in termini di tempo virtuale medio dei processi, aumentare beta significa avere un minor sovraffollamento dei processi sul buffer, vi sarà un minor numero di processi addormentati ed una maggiore probabilità per ognuno di questi di entrare nel buffer.