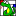Inheritance diagram for wx.html.HtmlParser:

Classes derived from this handle the generic parsing of HTML documents: it scans the document and divide it into blocks of tags (where one block consists of beginning and ending tag and of text between these two tags).
It is independent from wx.html.HtmlWindow and can be used as stand-alone parser.
It uses system of tag handlers to parse the HTML document. Tag handlers are not statically shared by all instances but are created for each wx.html.HtmlParser instance. The reason is that the handler may contain document-specific temporary data used during parsing (e.g. complicated structures like tables).
Typically the user calls only the Parse method.
See also
Adds handler to the internal list (and hash table) of handlers. This method should not be called directly by user but rather by derived class’ constructor.
This adds the handler to this instance of wx.html.HtmlParser, not to all objects of this class! (Static front-end to AddTagHandler is provided by wx.html.HtmlWinParser).
All handlers are deleted on object deletion.
Parameters:
Parses the source from begin_pos to end_pos - 1.
Parameters:
Returns pointer to the file system.
Returns:
Parameters:
Returns:
string
Returns pointer to the source being parsed.
Returns:
string
Setups the parser for parsing the source string. (Should be overridden in derived class).
Parameters:
Proceeds parsing of the document. This is end-user method. You can simply call it when you need to obtain parsed output (which is parser-specific).
Parameters:
Returns:
Forces the handler to handle additional tags.
The handler should already be added to this parser.
Parameters:
Sets the virtual file system that will be used to request additional files. (For example <IMG> tag handler requests wx.FSFile with the image data.)
Parameters: