Infinity77



Copyright
- Python Based
If you have any request, or you would like to know how I built some of these software and interfaces, please feel free to drop me an e-mail.
Copyright Section
In this section you will find the description of a number of software (actually, only a part of them) that I wrote during 5 years of work in ENI. These software integrate and improve all the software packages we have bought for the Reservoir Modelling.
Note: on these images, all the rights are reserved. These software are protected by copyright or by intellectual property.
GlobAll
implements different mathematical global (and local) optimization
techniques in order to apply them to History Matching problems.
It is written in Python, using wxPython for the Graphical User
Interface (GUI), but it contains also parts of code in Matlab, Fortran
and C/C++.
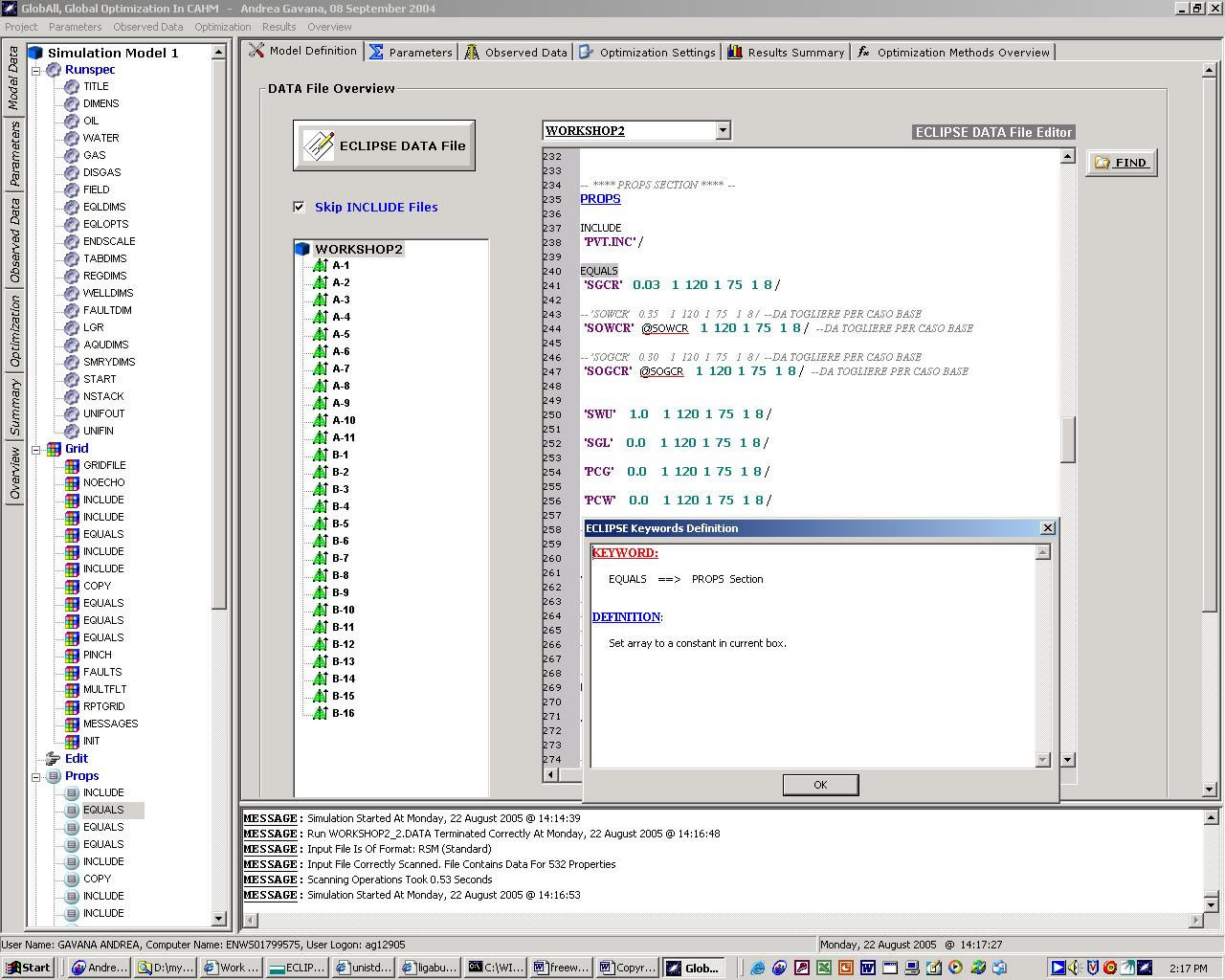
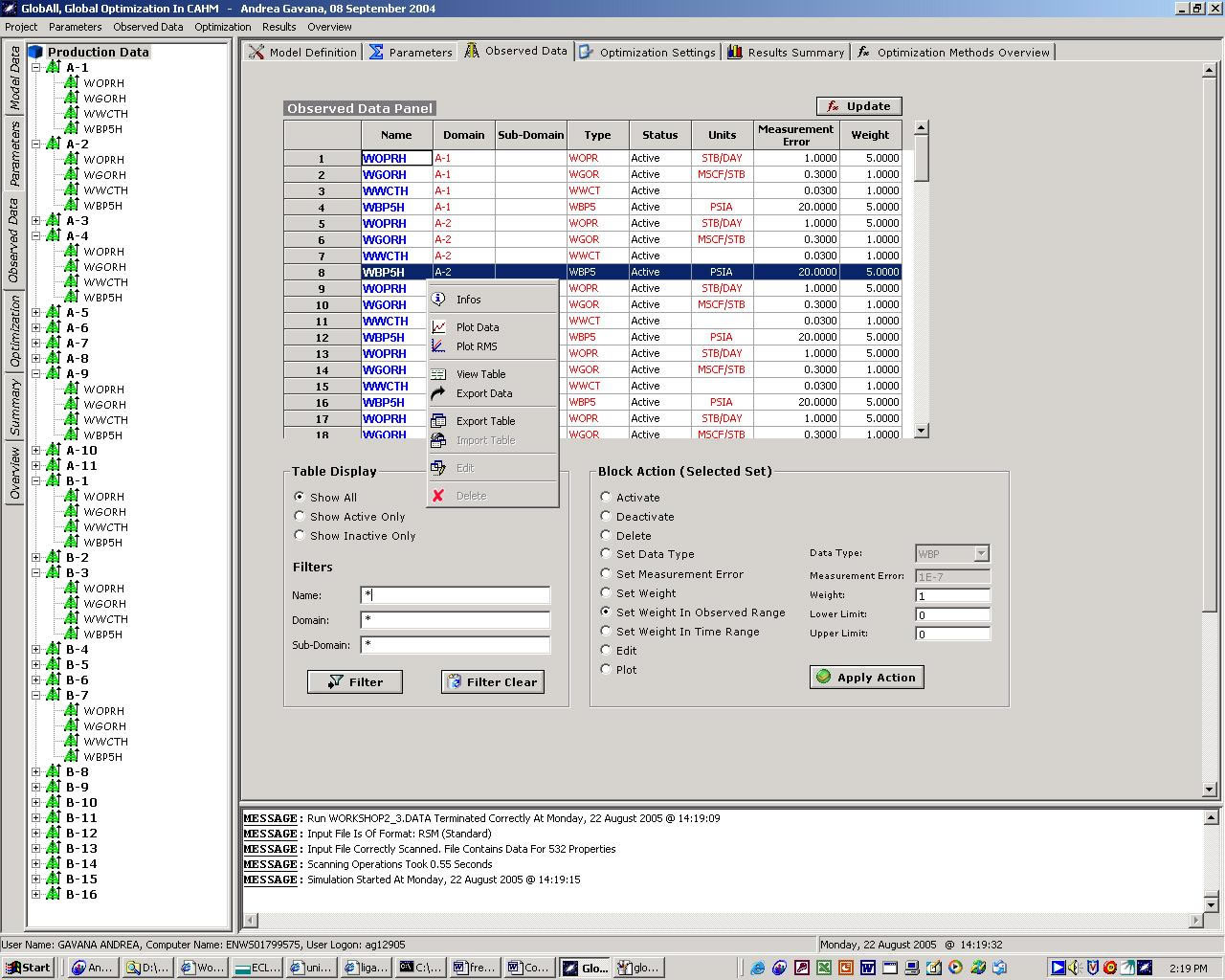
The software is able to import whatever DATA file of ECLIPSE (our reservoir simulation software) and to define any number or type of parameters inside this file. Moreover, GlobAll is able to process input data coming from ECLIPSE outputs, Graf, SimOpt and other file formats used internally in ENI.
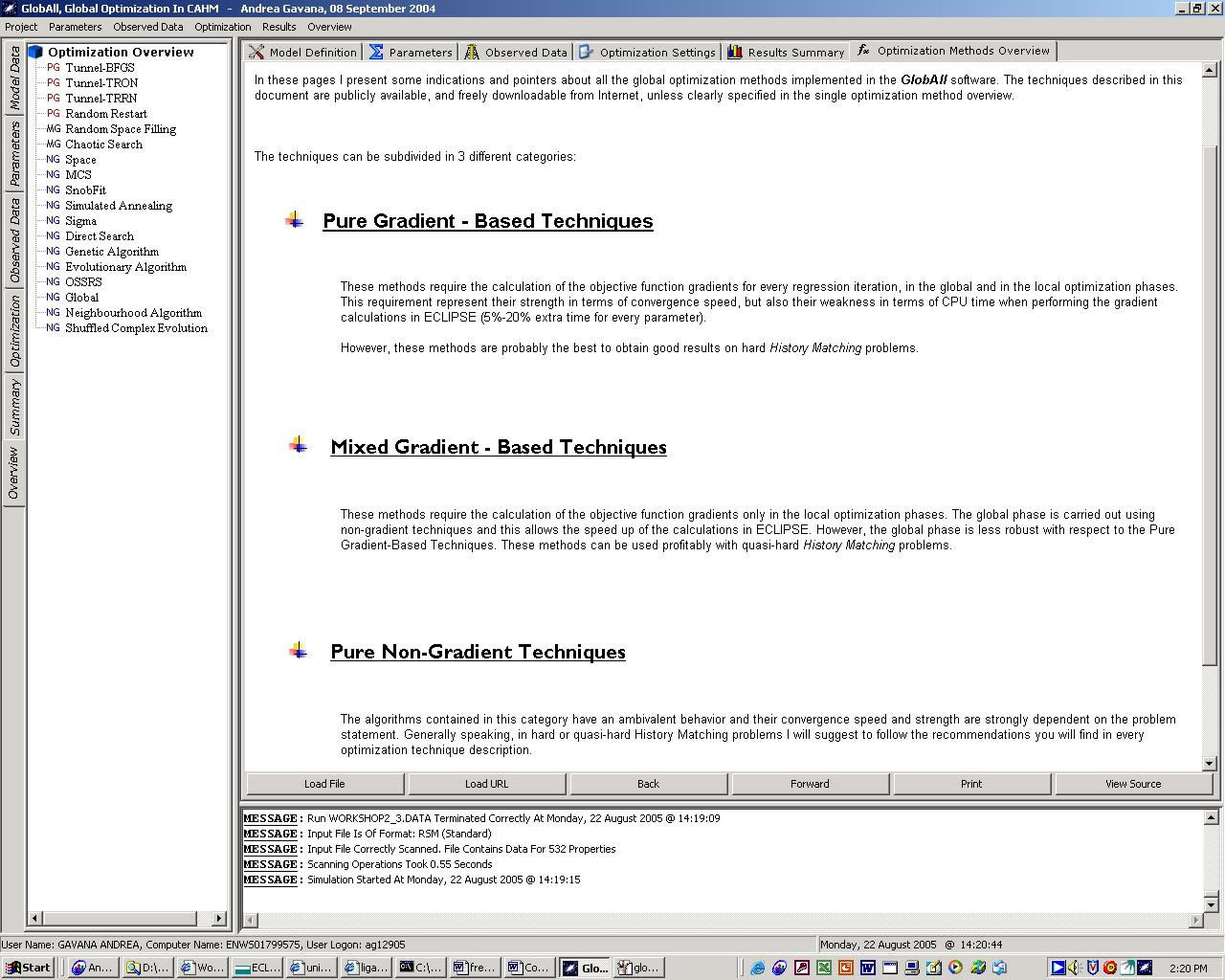
Using the GUI, it is possible to choose between 18 different global optimization techniques; these techniques are recognized as the best in the mathematical literature.
The GlobAll preprocessor is able to identify the user-defined parameters, and to rewrite the ECLIPSE DATA file accordingly. Next, GlobAll starts automatically the reservoir simulator, waits for the run completion (that is monitored in real-time) and it post-processes the ECLIPSE results. If necessary, GlobAll will continue with the optimization as outlined above.
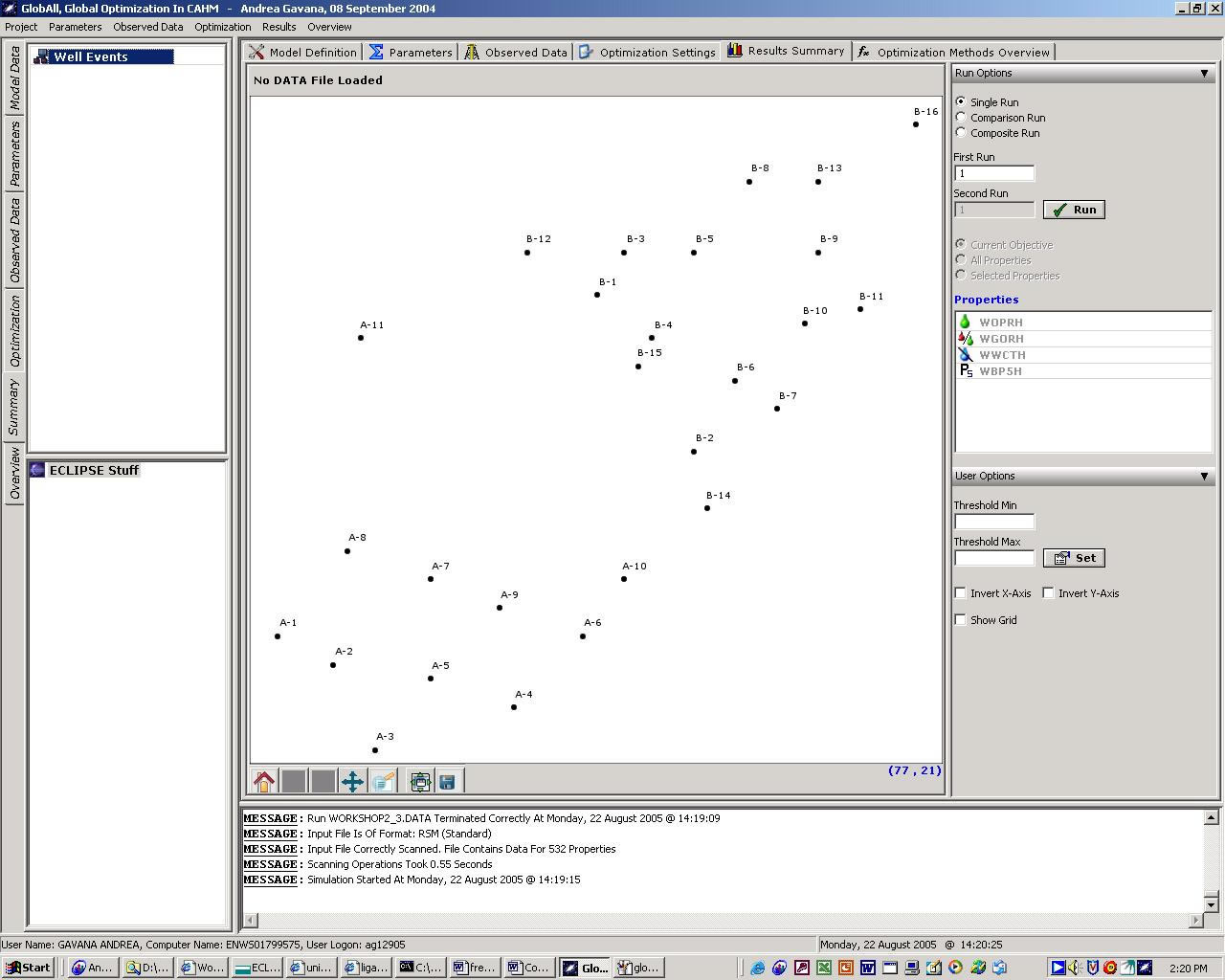
The software has a lot more functionalities and options, but I would not describe them, I have to be short. Please take a look at the images in order to figure out how GlobAll looks like.
The source code is still not complete, but we are seeing the end. At present, only the Python code has about 50000 lines.
 |
 |
 |
 |
 |
 |
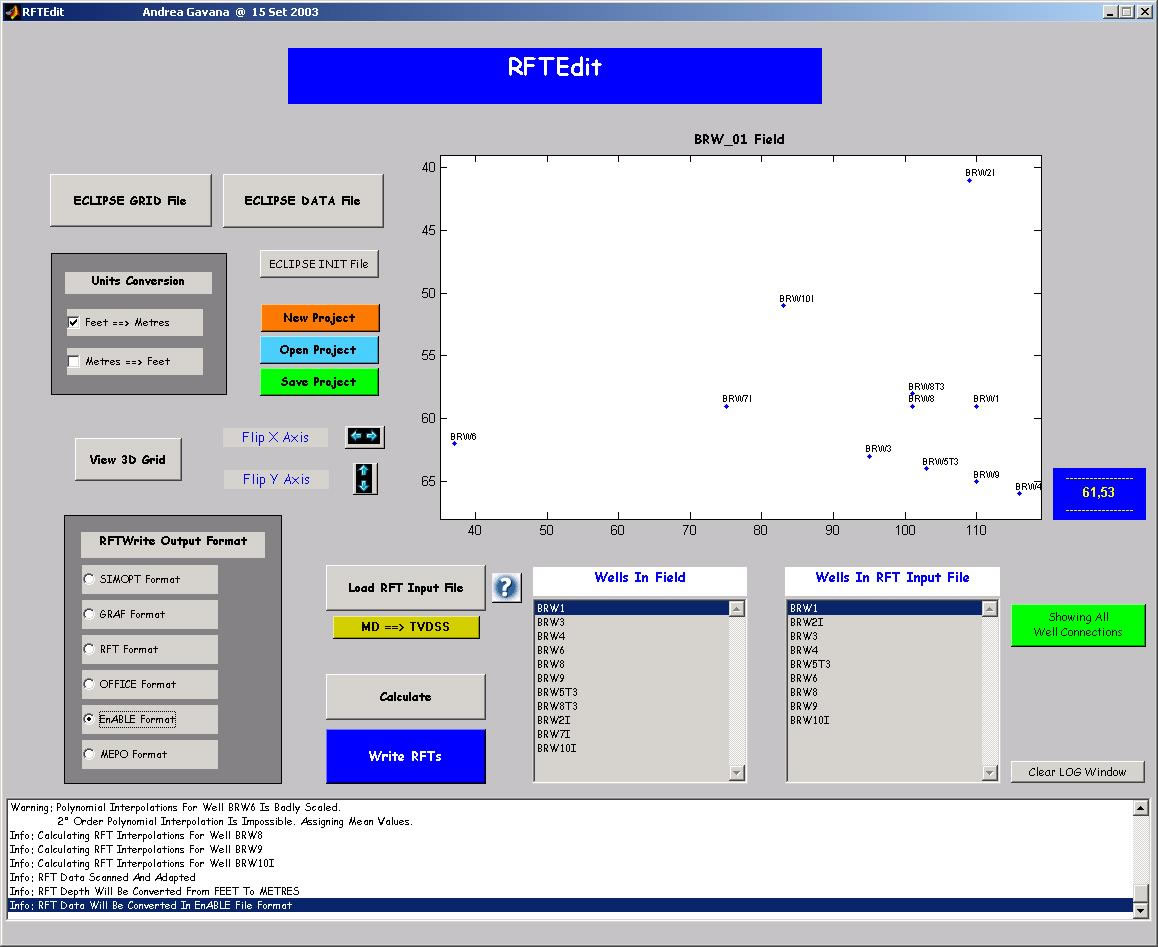
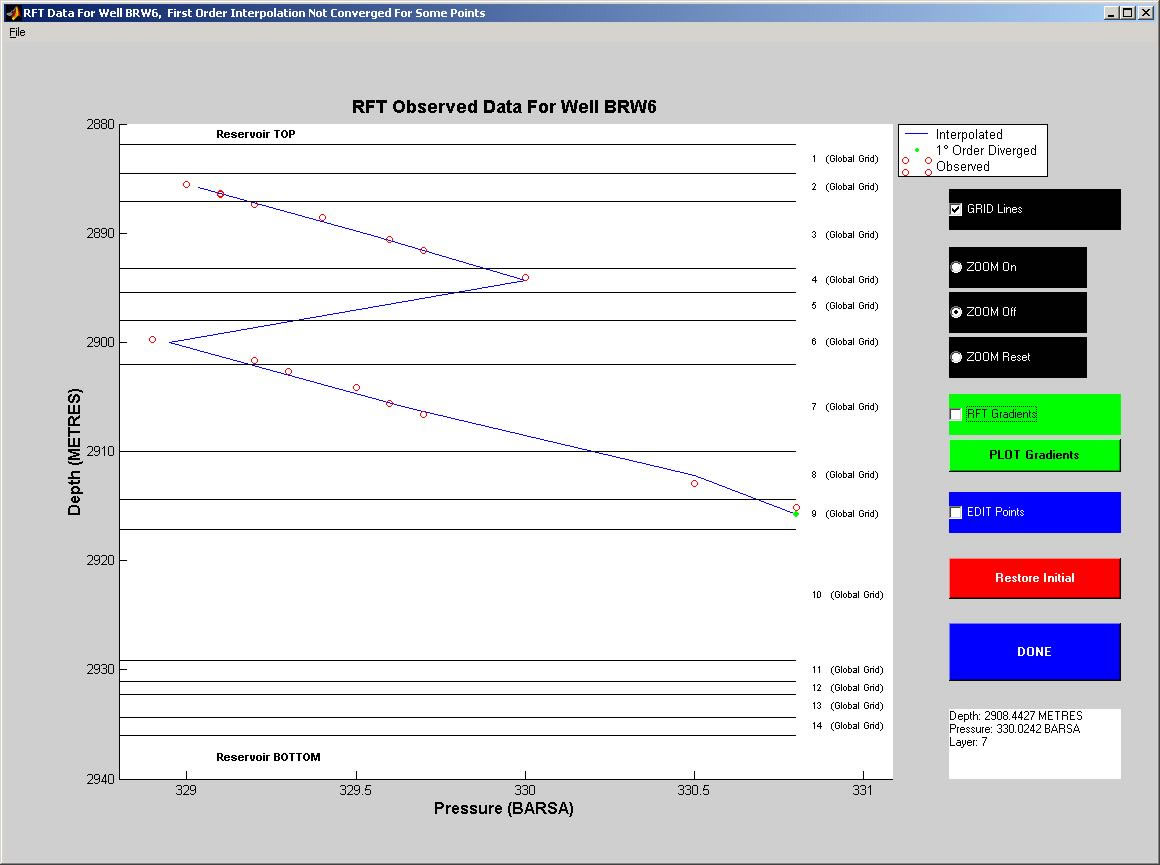
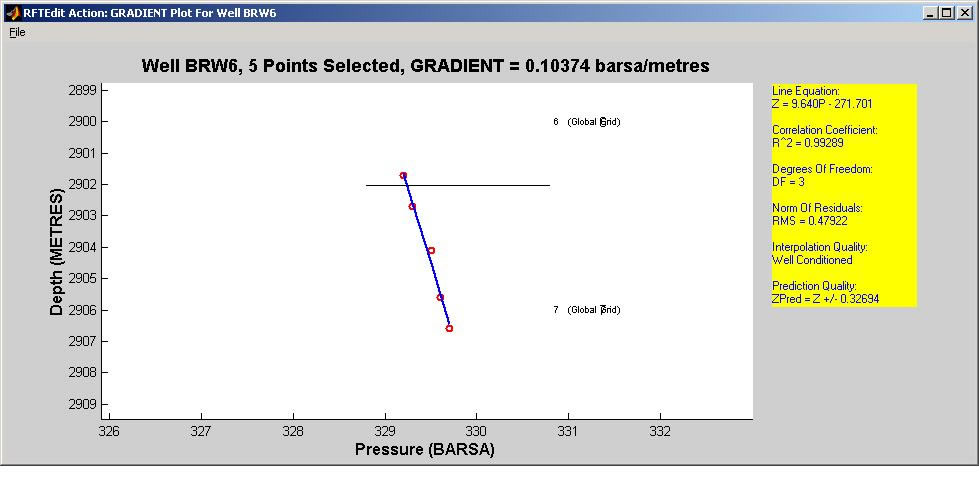
This software has been designed in order to handle RFT pressure data coming from real life field measurements, in an oil/gas reservoir. RFTEdit is able to pre-process the data, give the user the possibility to edit and analyze them and, at the end, to export the analyzed results in a file format compatible with one of our 5 Computer-Aided History Matching software.
The GUI is highly user-friendly, and allows the user to customize a lot of options. Moreover, it has a lot of functionality for the RFT analysis.
RFTEdit has been written in Matlab 6.0, which has very powerful functionalities regarding GUI design and development.
 |
 |
 |
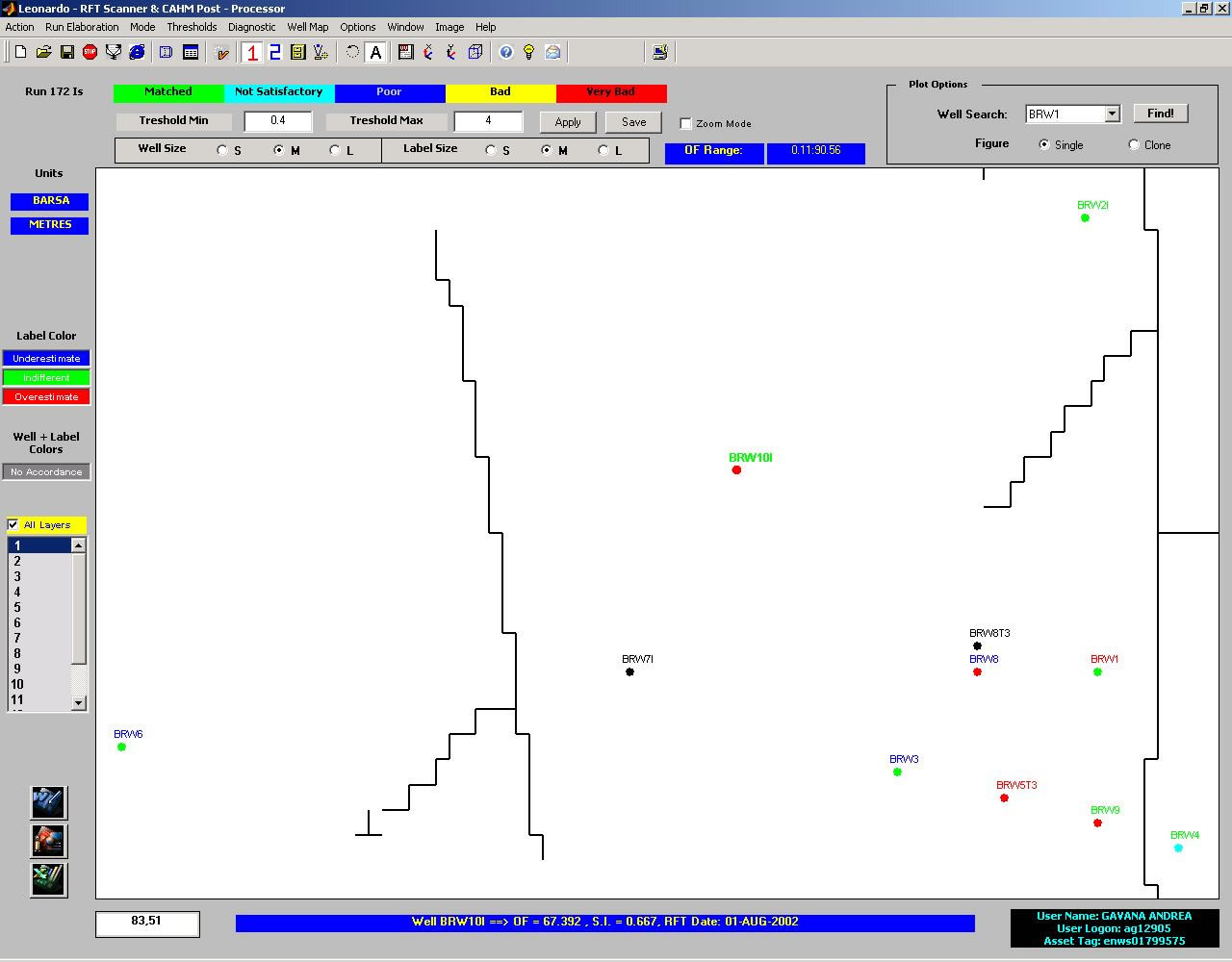
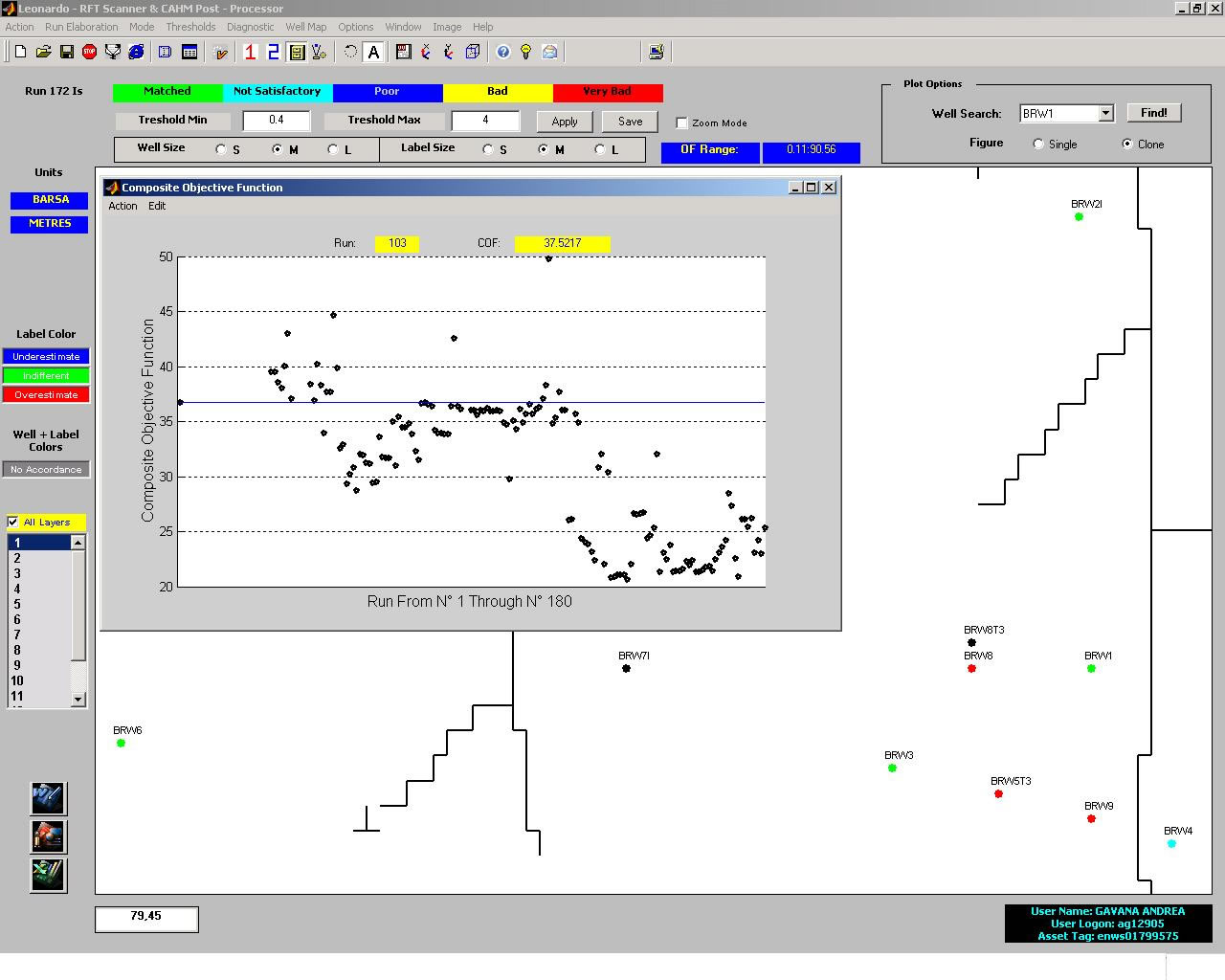
Leonardo
represents the conclusion of the RFTEdit project; it is a very powerful
tool that allows the user to analyze RFT ECLIPSE simulation results.
The RFT raw data analyzed and exported with RFTEdit are easily loaded
and integrated in Leonardo. The latter is able to scan ECLIPSE output
files that contain RFT simulated data and to compare them with the
observation data (with a mathematical comparison, using an objective
function definition). In this way, the RFT History Matching becomes
fast and very easy, with a powerful software, with a capturing GUI.
Leonardo includes many more options, but I need to be short. So, look at the images!
Leonardo has been written in Matlab 6.0, which has very powerful functionalities regarding GUI design and development.
 |
 |
 |
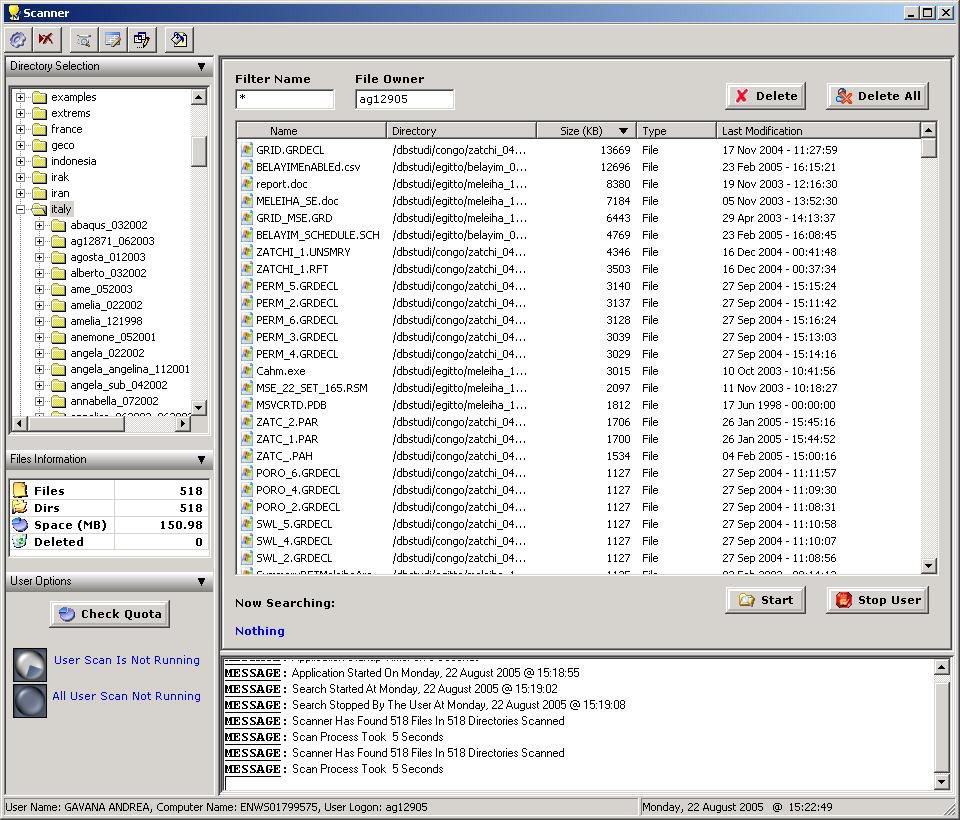
Scanner is a simple utility that I wrote in one day. Like many other software I have implemented, it is written in Python with wxPython as a graphical front-end.
Despite
the power of our PCs, it is usual for us to have problems regarding
free hard disk space, especially on Unix machines.
So, in order to (possibly) eliminate some old files or to locate some
lazy user that does not keep his/her directories clean, I have created
scanner. The tool is able to scan and analyze whatever directory that
is visible from the PC (not necessarily a file system) and to report,
for a particular user, the number of files belonging to him, their size
and other useful information.
Moreover, it is possible to analyze an entire file system (in our case,
1 TB of data) in order to create a list of “bad”
users: these users are surely occupying too much hard disk space with
respect to others.
 |
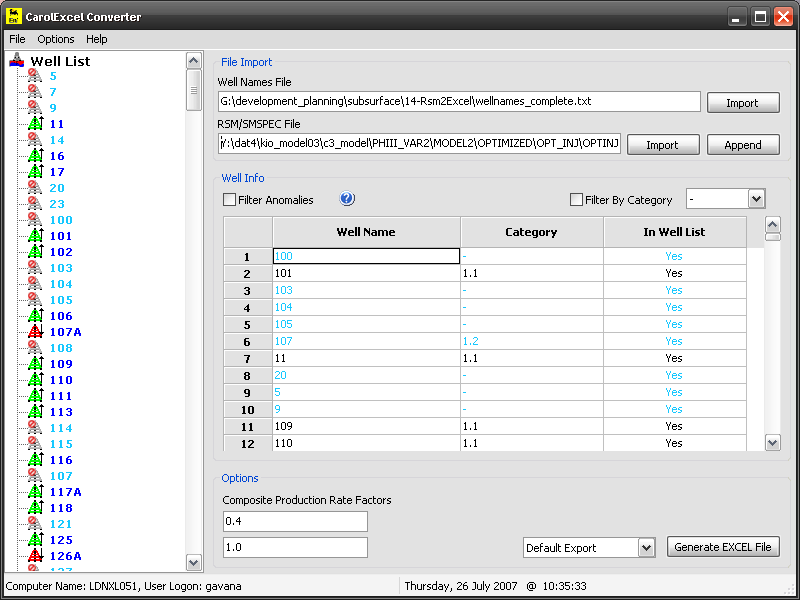
This software has been termed CarolExcel in honour to Carolina, who helped me so much during my work period in London. This program scans ECLIPSE SUMMARY files and it allows to categorize production/injection wells, allocate production data as a function of well completion depth and to export profiles (for wells, groups and field) to Excel.
CarolExcel is written in Python with wxPython as a graphical front-end: it has now reached version 5.1 and it has been the most used software in our group during the last year.
 |
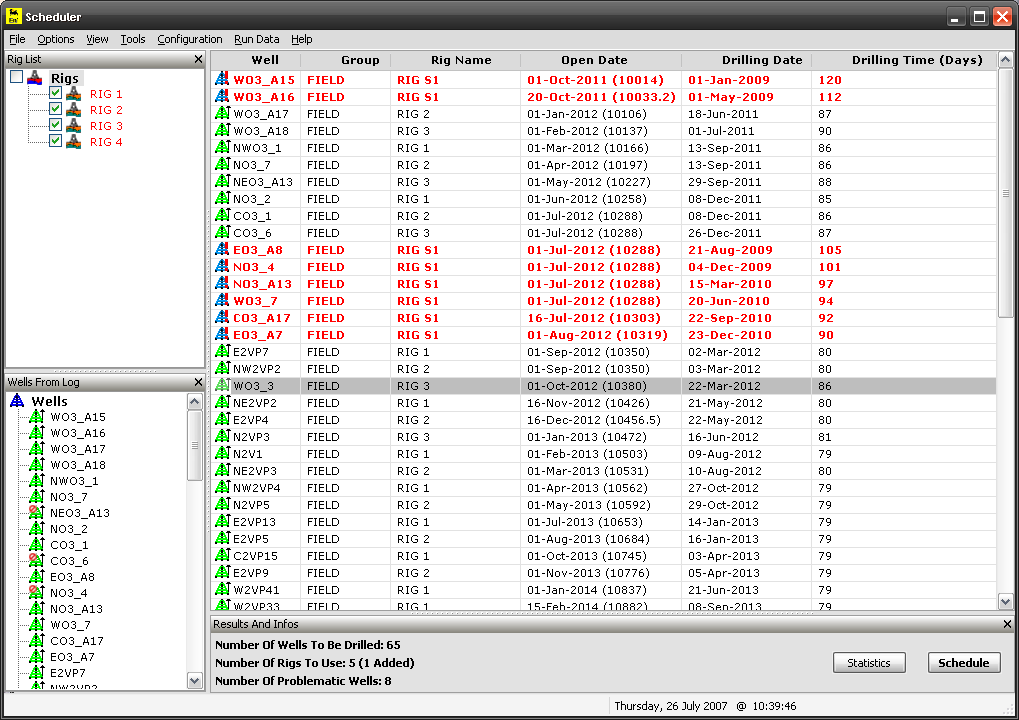
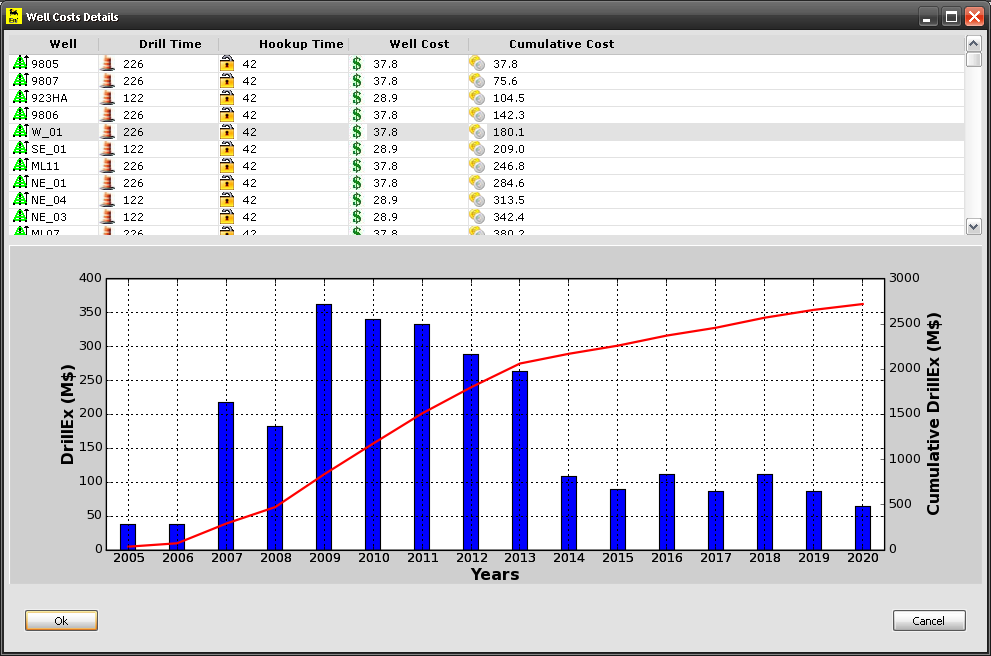
Scheduler
Scheduler born almost at the beginning of my London experience, during a period when we struggled to calculate the number of rigs required to drill a specified number of wells, without overlapping and by optimizing the drilling schedule. Using mathematical non-linear integer optimization techniques, Scheduler is now able to handle whatever well configuration minimizing the number drilling rigs. It also incorporates concepts like learning curves, probabilistic cost scenarios and it accomodates for possible delays in drilling wells.
Scheduler is written in Python with wxPython as a graphical front-end: it has now reached version 4.8, after which I have no more ideas on what to add to this masterpiece ;-)
 |
 |
 |
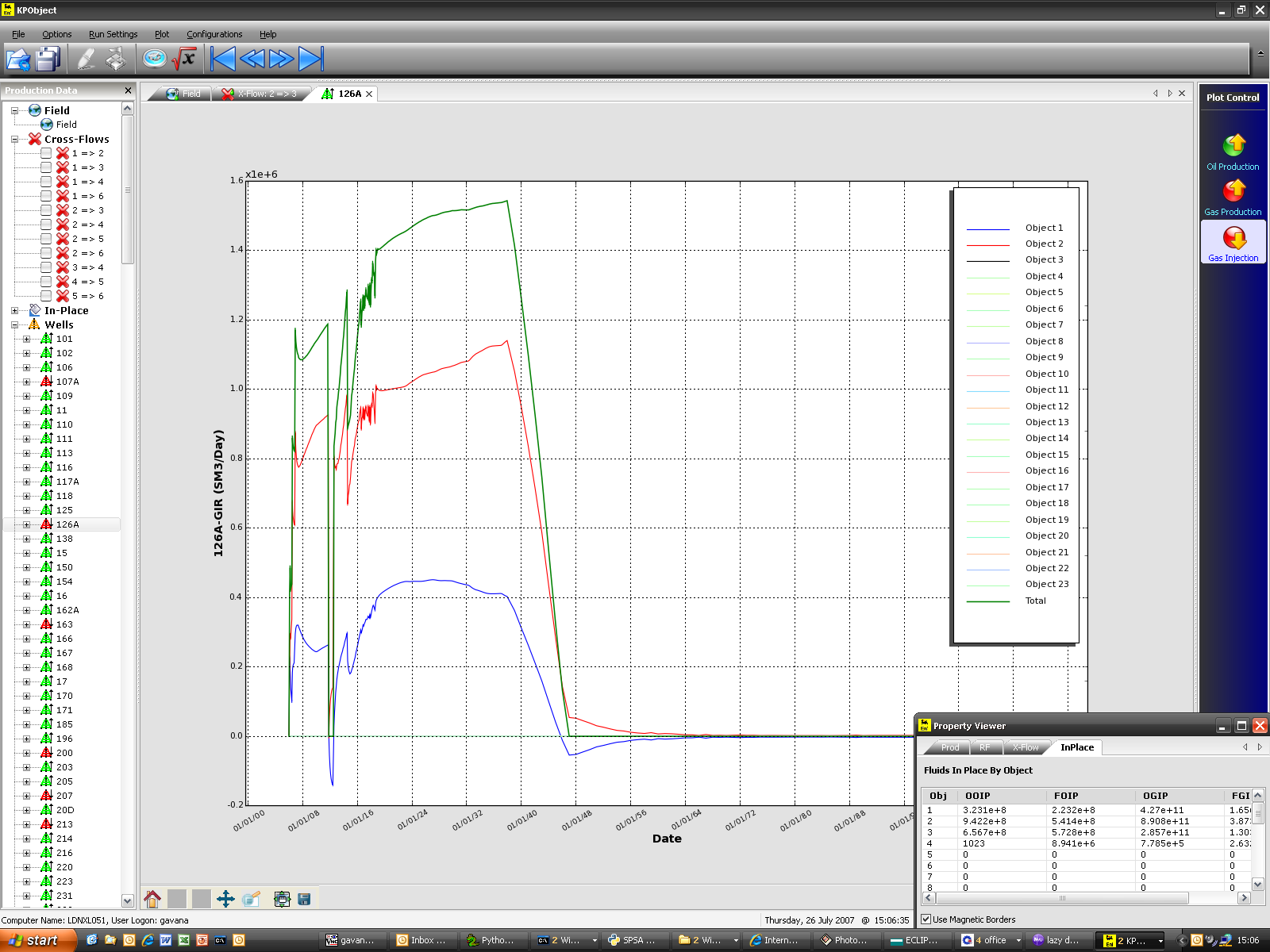
KPObject
KPObject has been created to calculate recovery factors per field region from ECLIPSE simulations: ECLIPSE 300 does not report data on a region basis, so few tricks are necessary to extract those kind of information, including reading a huge output file (300 MB) as fast as possible. Different kind of results are presented in the GUI, such as field production profiles, inter-region crossflows, fluids in place, and well/connection production data on a region basis.
This software has also been presented to our major headquarter in Aksai (Kazakhstan) in order to finish on time the work on Reserve Redetermination for our oil/gas field.
KPObject is written in Python with wxPython as a graphical front-end.
 |
 |
 |
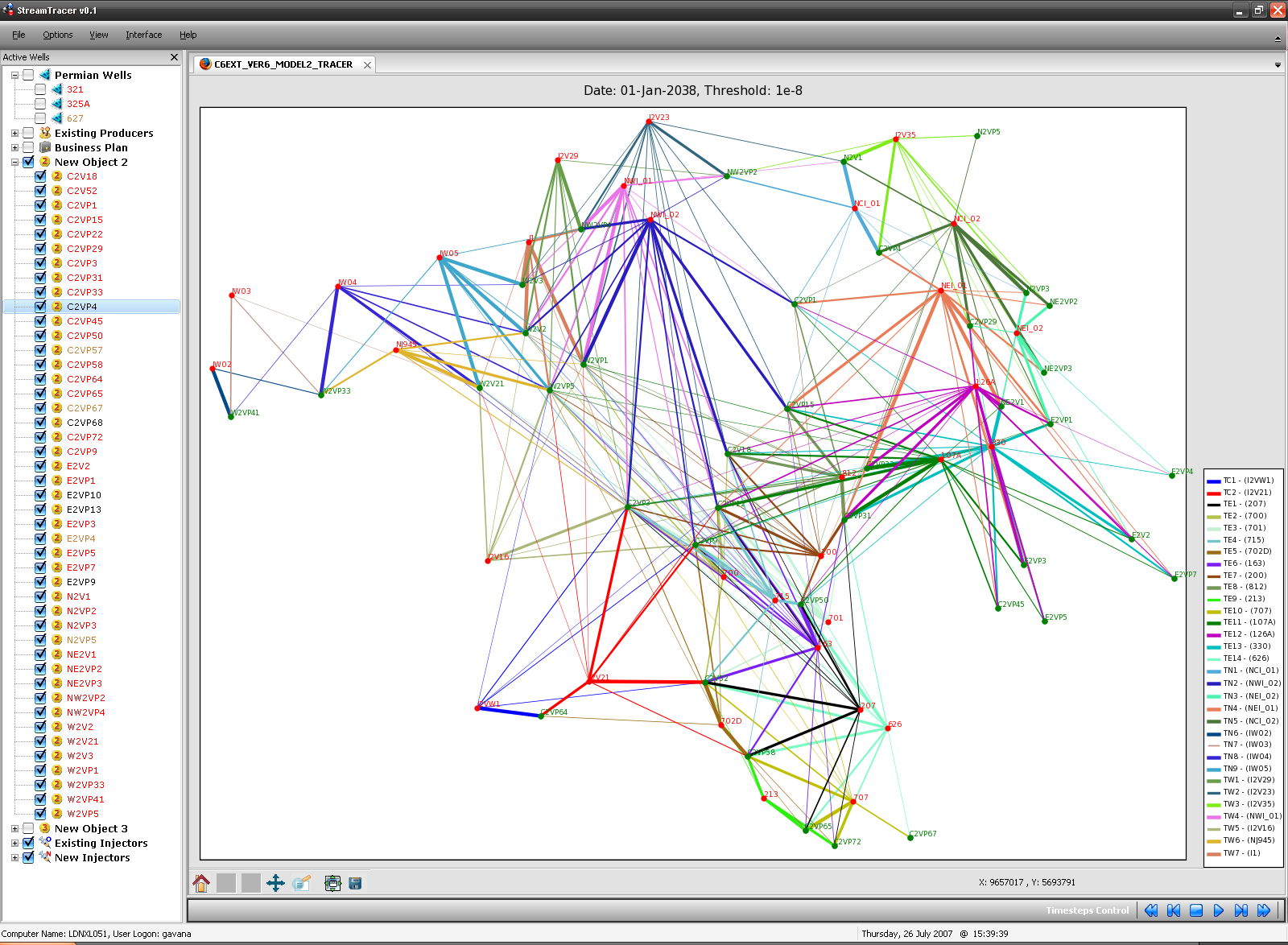
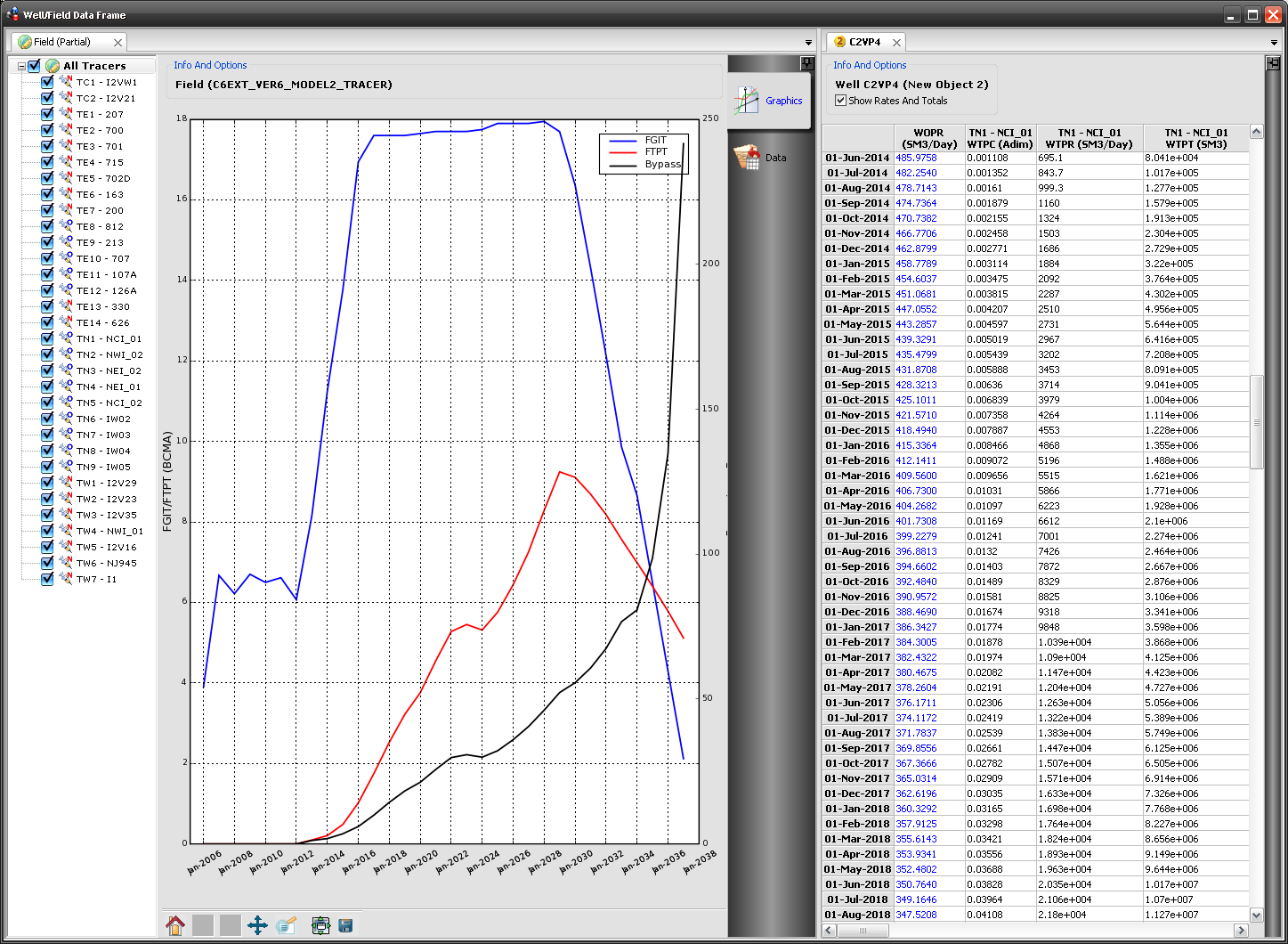
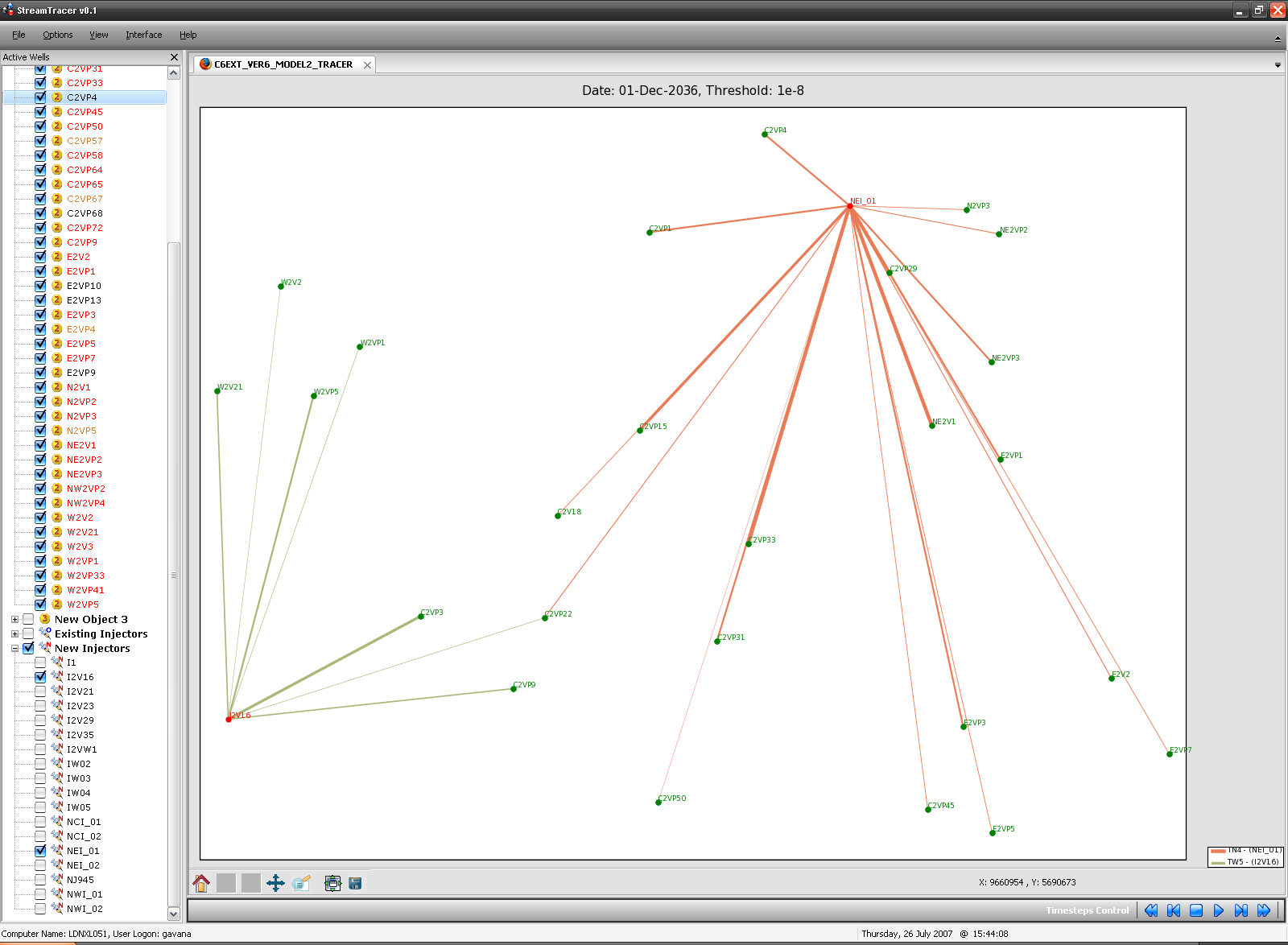
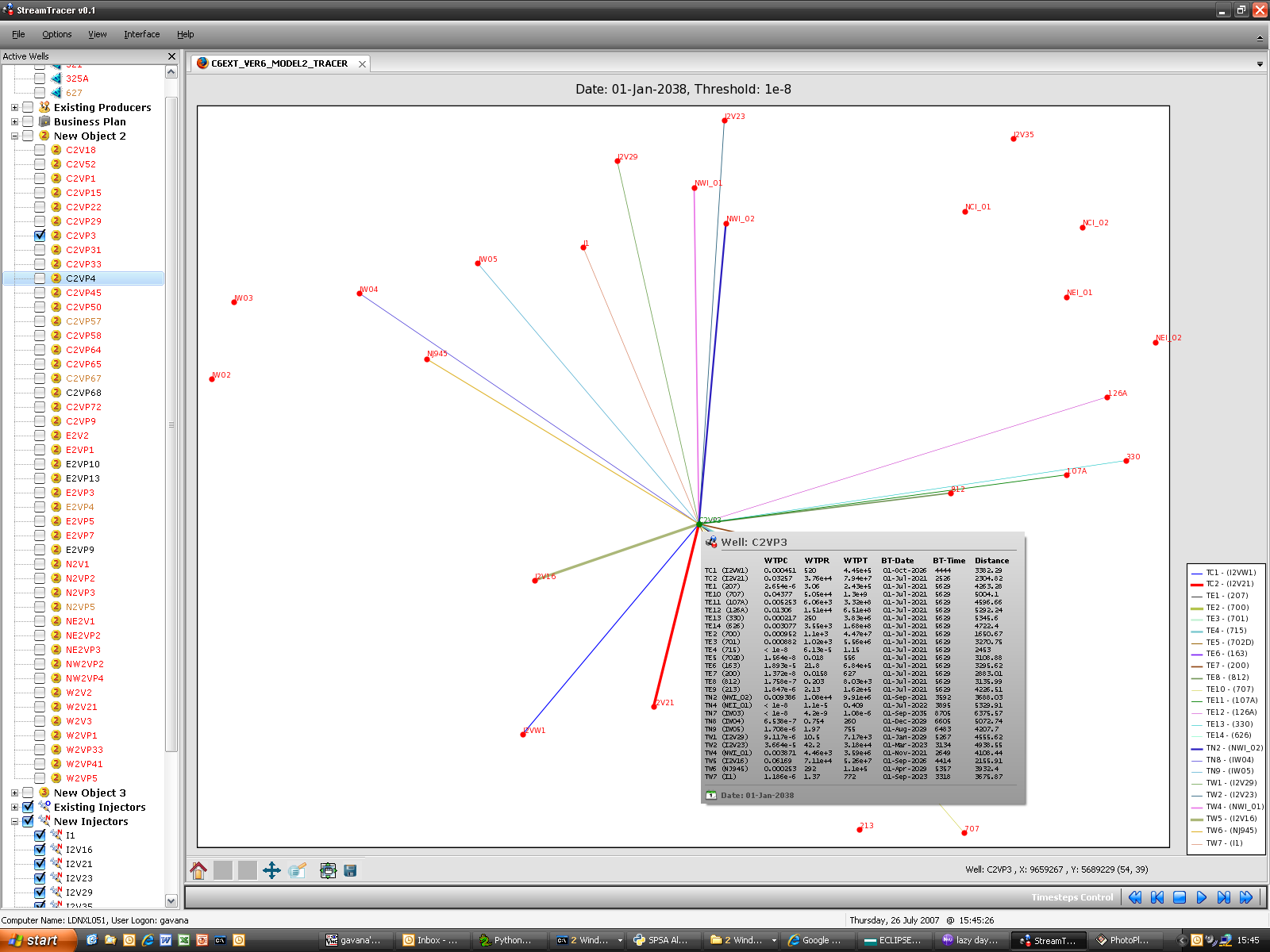
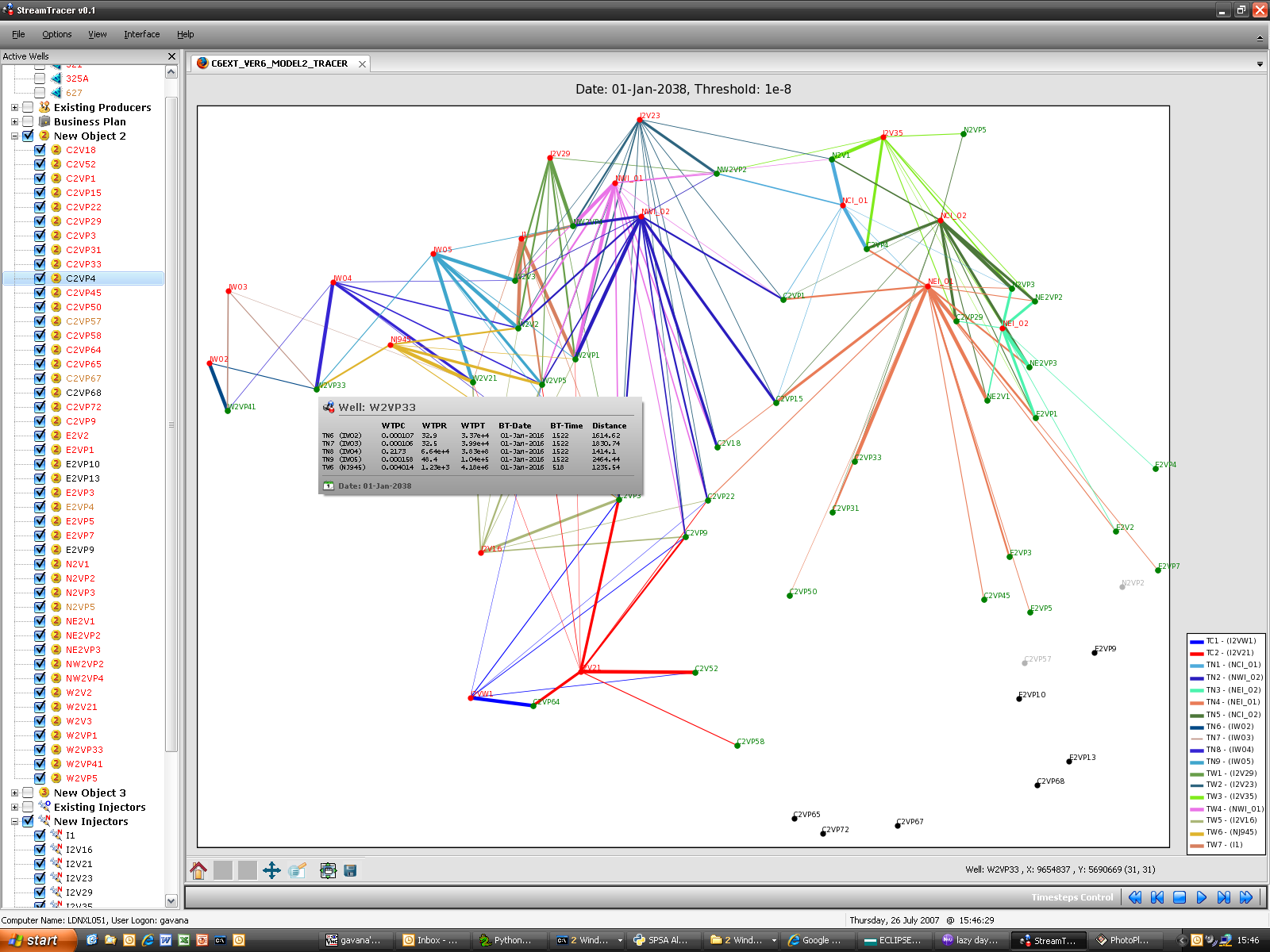
StreamTracer
This software has been created to analyze in a straightforward and visual way the relationships between injection wells and production wells, in terms of gas-cycling and/or bypass. In order to understand if a producer is simply recycling the injection gas (and not extracting the gas from the reservoir), I have used simulated radioactive tracers inside ECLIPSE 300. Using the output data from the simulator, is then possible to assess the tracer concentration, rate and cumulative production for every producer well.
StreamTracer is particularly useful in the well location optimization phase, in which we tried to maximize the liquid recovery while minimizing the tracer production (and thus the gas-cycling). As the visual inspection is much easier than the numerical analysis of hundreds of MB of data, the optimization phase has been sped up quite a lot.
 |
 |
 |
 |
 |
 |
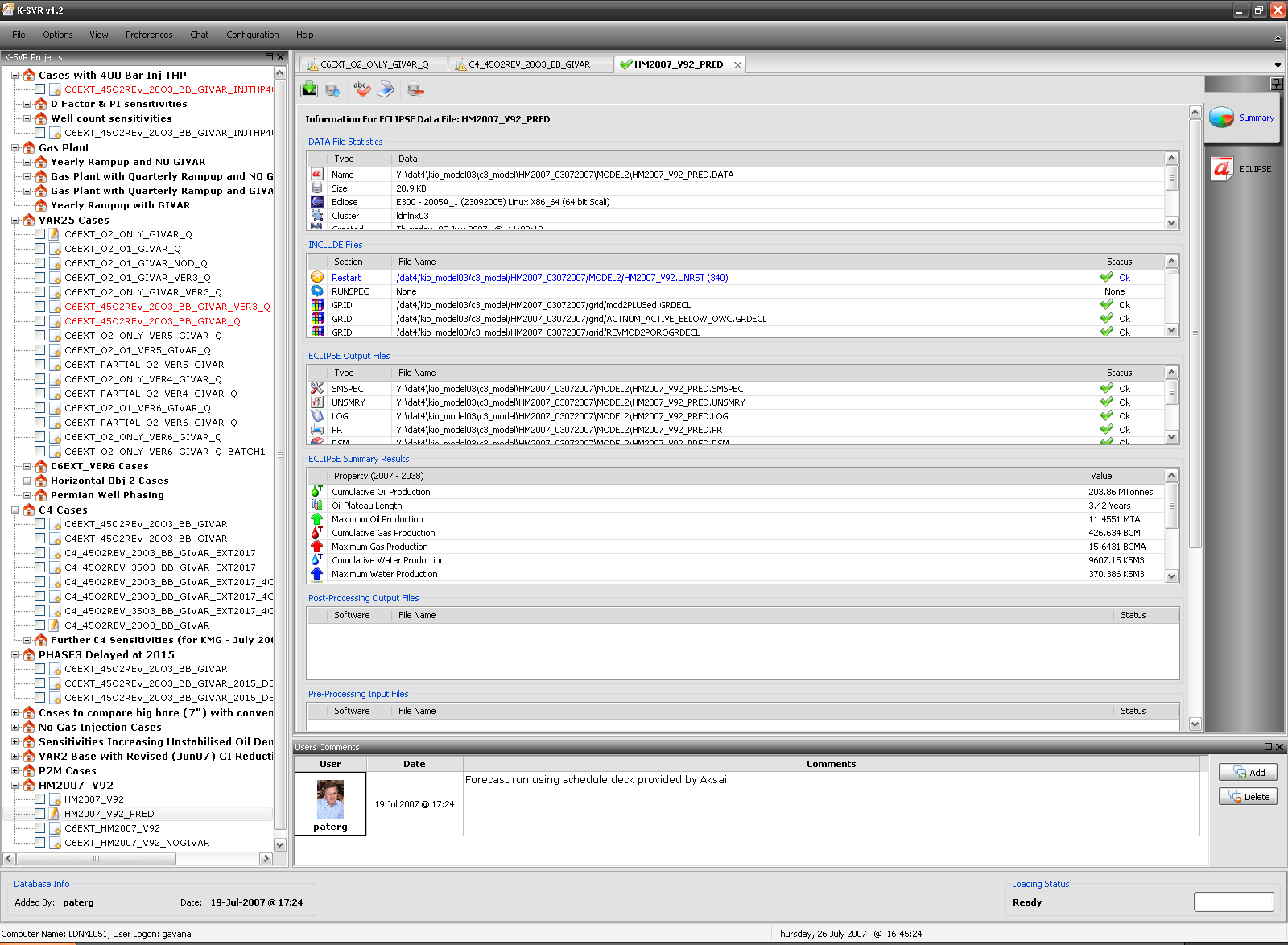
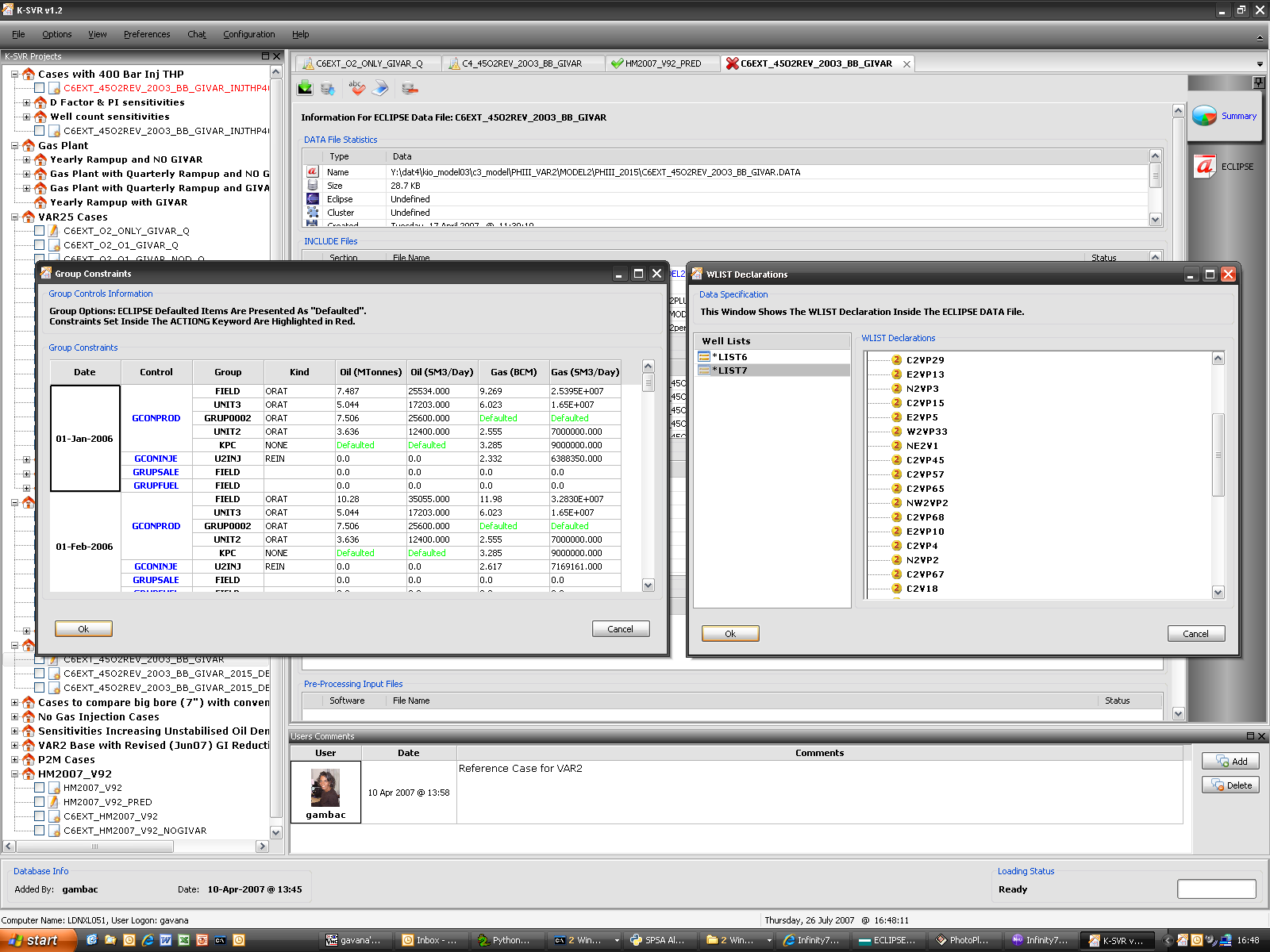
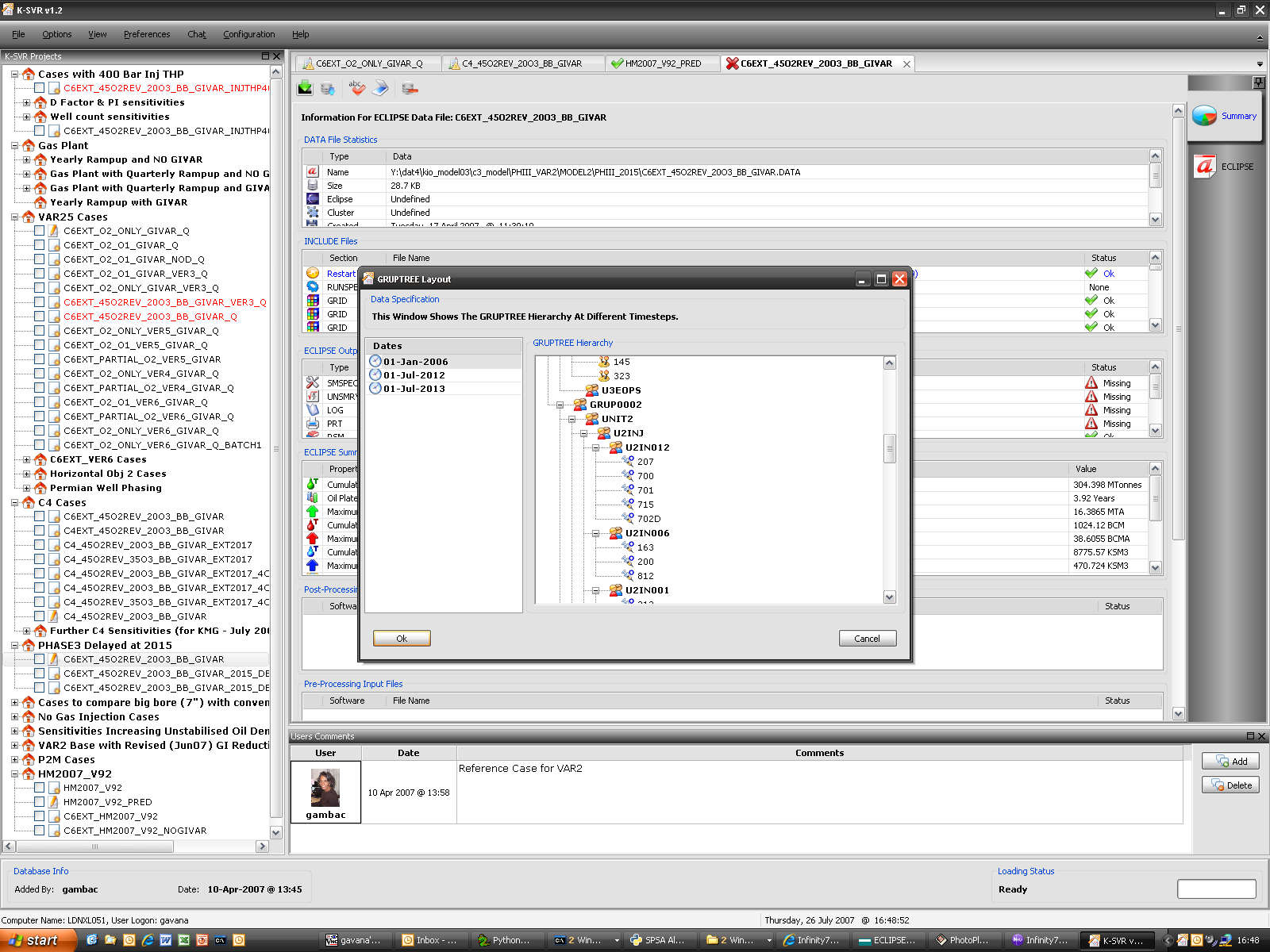
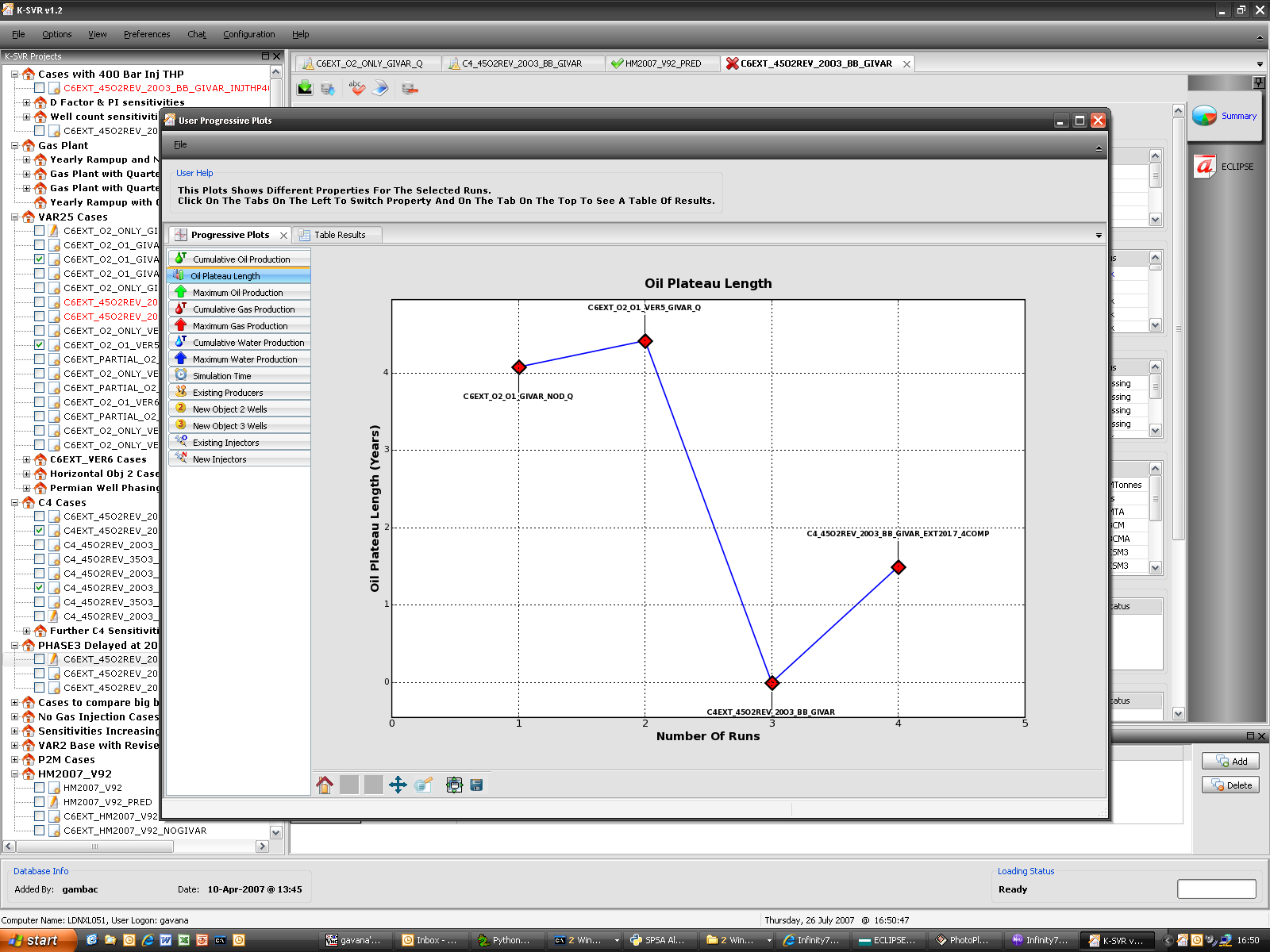
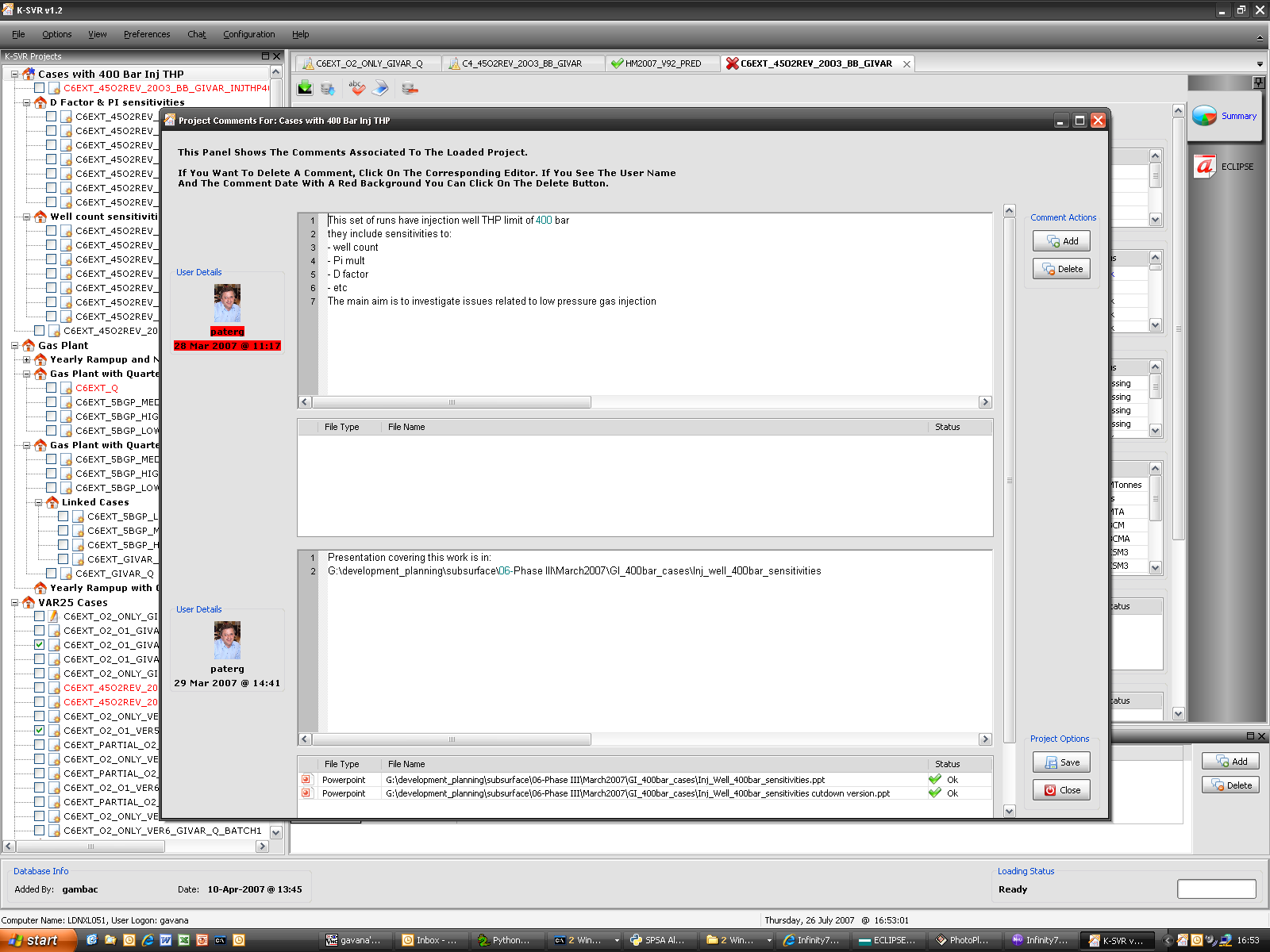
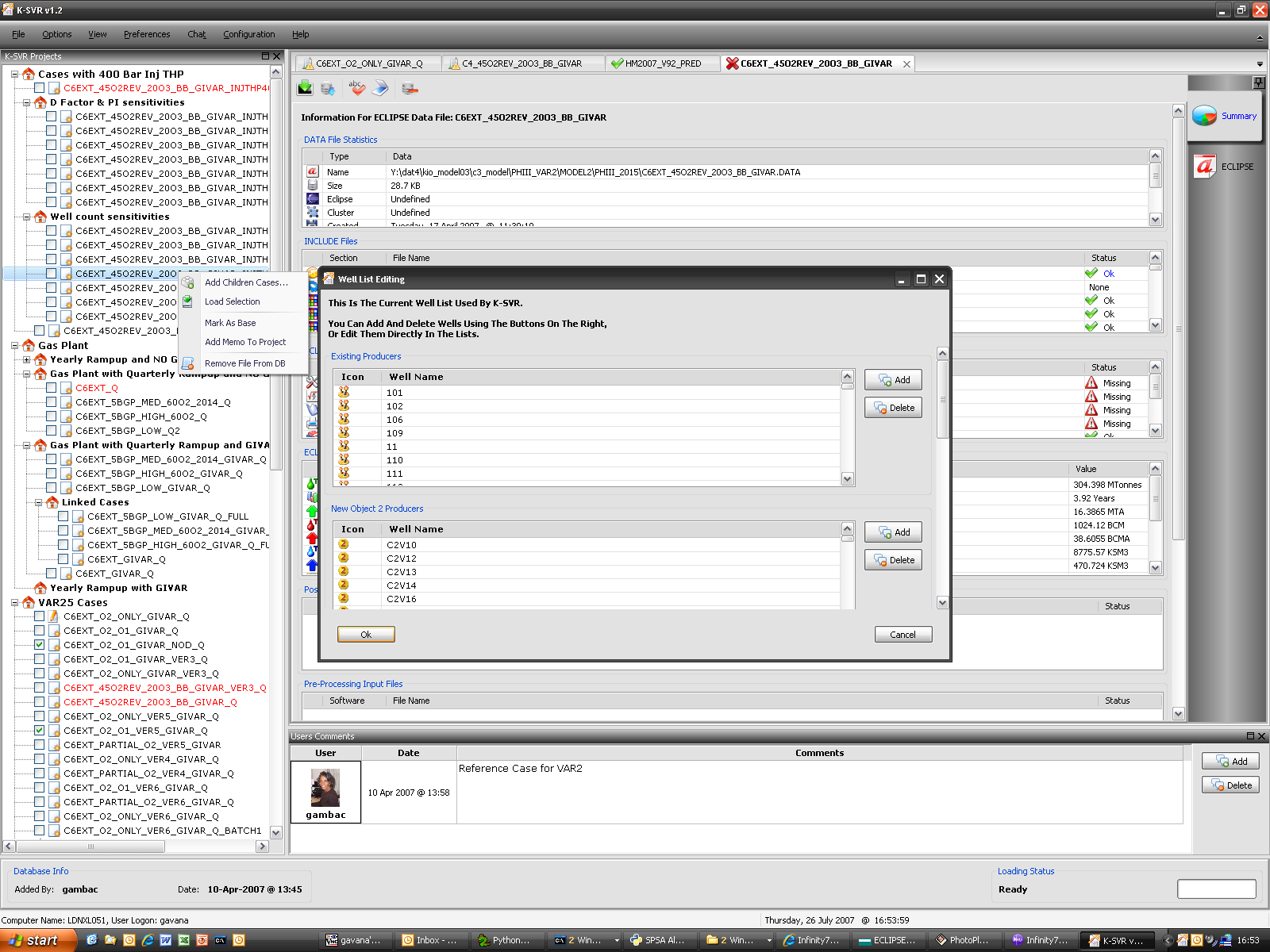
K-SVR
K-SVR is the answer to a problem that obsessed us for a while: we do a very intense work on simulations, producing about 6,000 reservoir simulations per year. What can we do to keep track of all the modifications we make to an input deck file so that we could be able to reconstruct all the steps we made in the past? How can we precisely identify why a particular change has been implemented? Where are the generated output files and which were the results of a particular simulation?
After struggling with a modified SVN-like approach, I decided (wisely, in the end) to stick with a database implementation, storing deck files, results, production profiles, user information and whatever inside a common multi-user database: I then built around it a GUI based on wxPython, which uses a multi-threaded approach to poll the database and to save new results, while allowing our group of 7 people to work on it simultaneously if we wish to do so.
 |
 |
 |
 |
 |
 |
 |
 |
 |